
Moltbot 总体架构与核心概念
Moltbot 并非一个单一功能的聊天机器人,而是一个高度可扩展、以插件和 Skill 为核心的个人助理框架。它旨在通过模块化的设计,适应多样化的通信渠道与任务场景,为用户提供连贯且具备长期记忆的智能交互体验。本章将从宏观视角出发,剖析 Moltbot 的核心架构、关键组件以及其独特的工作模式,为后续深入探讨记忆系统和 Skill 管线奠定基础。
一、核心组件概览
Moltbot 的系统架构可以被解构为五个相互协作的核心部分,它们共同构成了从接收消息到最终响应的完整闭环。
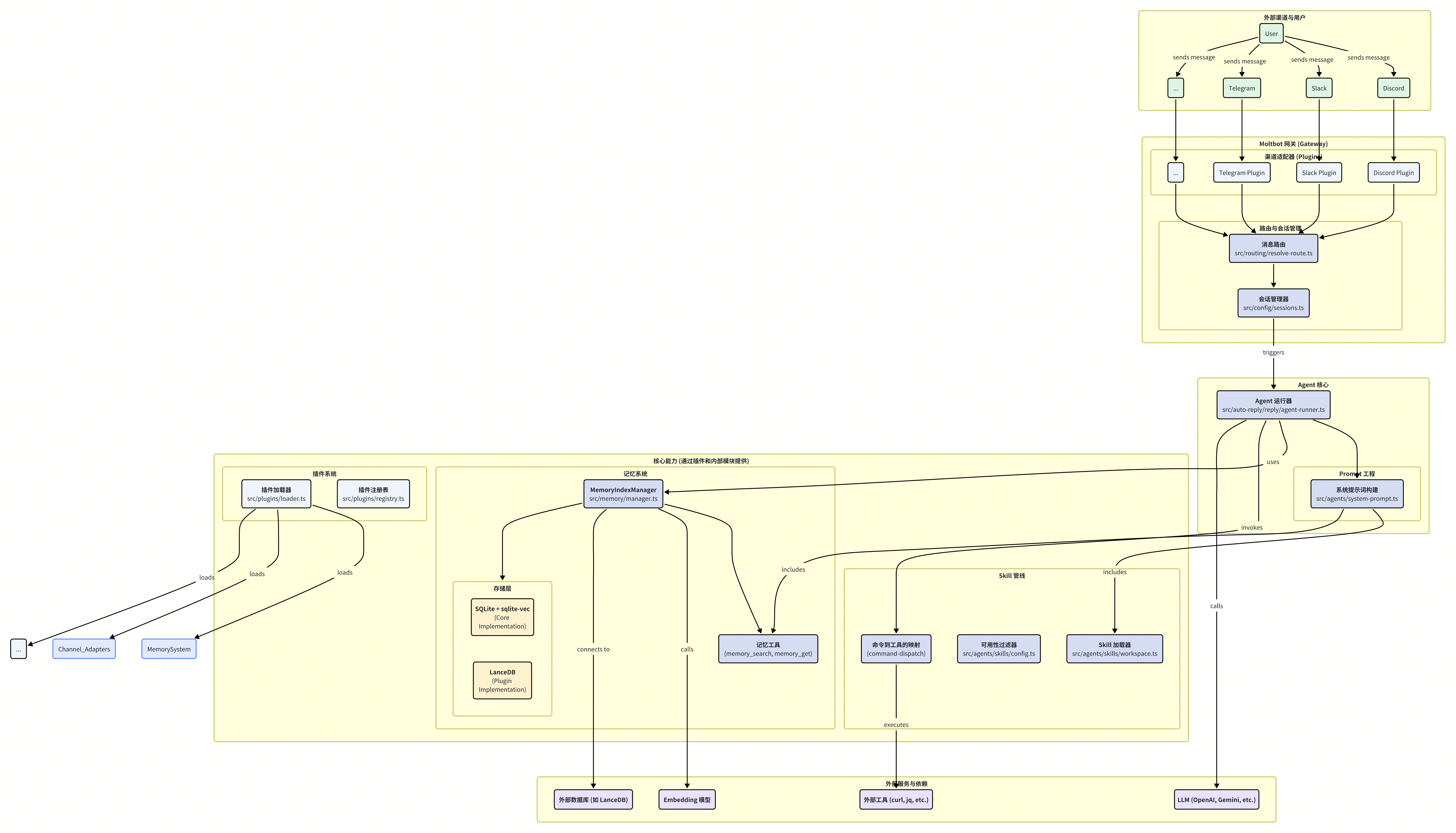
网关 (Gateway) 与渠道适配器 (Channel Adapters):网关是 Moltbot 与外部世界通信的入口。它通过一系列渠道适配器插件(如 Discord, Slack, Telegram 等)接入不同的消息平台。每个适配器负责处理特定平台的协议转换、消息收发以及事件监听,将外部消息标准化后送入系统内部。
消息路由与会话管理 (Routing & Session):当消息进入网关后,路由系统 (
src/routing/resolve-route.ts) 会根据预设的规则(定义于moltbot.json的routing.bindings中),决定该消息应由哪个 Agent 实例来处理。匹配成功后,会话管理器会为这次交互分配或复用一个唯一的会话(Session),确保对话上下文的隔离与连续性。Agent 核心 (Agent Core):这是决策与推理的核心。Agent 运行器 (
src/auto-reply/reply/agent-runner.ts) 接收到路由过来的消息后,会启动一次完整的处理循环。它首先会通过 Prompt 工程模块 (src/agents/system-prompt.ts) 构建一个包含任务指令、可用工具、记忆片段和上下文的系统提示词(System Prompt),然后调用大语言模型(LLM)进行推理。核心能力 (Core Capabilities):Agent 的强大能力源于两个关键的子系统:
记忆系统 (Memory System):负责信息的长期存储和检索。它能自动从对话中捕获关键信息,并在需要时“回忆”起相关内容,为 Agent 提供超越当前对话窗口的上下文感知能力。
Skill 管线 (Skill Pipeline):定义了 Agent 可使用的工具集。每个 Skill 描述了一项具体能力(如查询天气、读取文件),管线负责发现、加载、过滤并向 Agent 展示这些能力。
外部服务与依赖 (External Services & Dependencies):Moltbot 依赖一系列外部服务来完成任务,包括用于推理的 LLM、用于向量化的 Embedding 模型,以及 Skill 执行时可能需要的外部 API 或命令行工具(如
curl,jq)。
二、工作模式:事件驱动的请求生命周期
Moltbot 的工作模式是典型的事件驱动模型。一次完整的请求生命周期清晰地展示了各大组件如何协同工作。
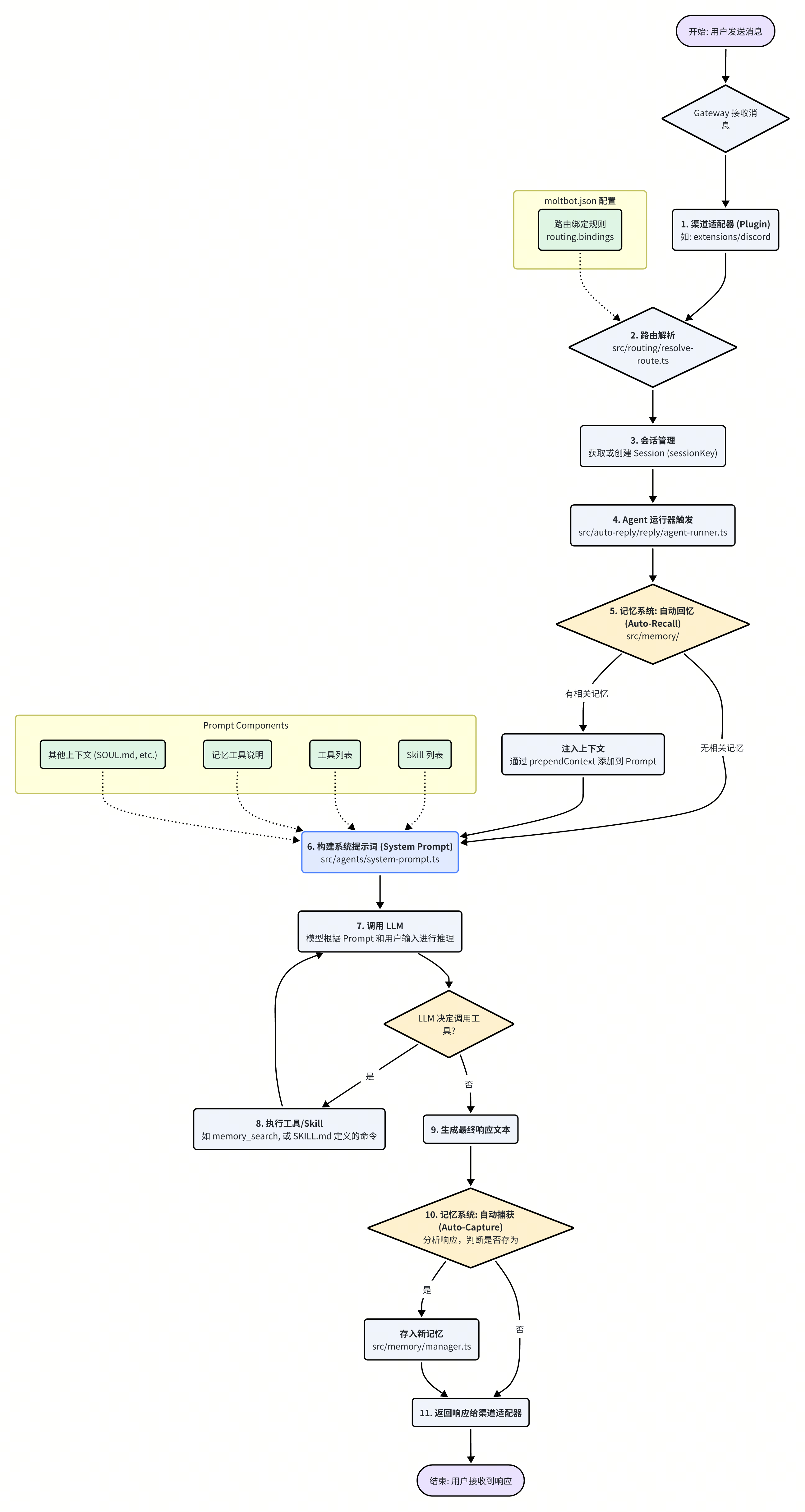
整个流程可以概括为以下几个步骤:
消息接收:用户通过任一渠道(如 Discord)发送消息。
渠道适配:对应渠道的插件接收到消息,并将其转发给网关。
路由决策:
resolveAgentRoute函数根据moltbot.json中的路由规则,为消息匹配一个 Agent 实例,并确定或创建会话sessionKey。Agent 触发:
agent-runner被激活,开始处理该会话的请求。自动回忆:在构建 Prompt 之前,记忆系统首先被触发,根据当前输入检索相关记忆,并将其注入到即将生成的 Prompt 上下文中。
Prompt 构建:系统综合用户输入、注入的记忆、可用的 Skill 列表以及固定的指令,构建出最终的系统提示词。
LLM 推理:将构建好的 Prompt 和用户消息一同发送给 LLM。
工具调用(可选):如果 LLM 的决策是使用某个工具,Agent 会解析其意图,执行相应的 Skill 或内置工具,并将结果返回给 LLM 进行下一步推理。这个过程可能重复多次。
生成响应:LLM 生成最终的文本回复。
自动捕获:在响应发送前,记忆系统会分析本次对话内容,判断是否有值得长期保存的信息,并自动将其存入记忆库。
响应返回:最终响应通过原渠道适配器返回给用户。
这个流程体现了 Moltbot 设计的核心思想:通过记忆和工具,将无状态的 LLM 调用转化为一个有状态、有能力的智能助理。
三、配置体系:moltbot.json 的核心地位
Moltbot 的灵活性和可定制性在很大程度上归功于其分层、统一的配置系统。所有核心行为,从 Agent 的性格到插件的启用,都由配置文件 moltbot.json 驱动。
核心配置文件通常位于 ~/.clawdbot/moltbot.json。其结构清晰,主要包含以下几个部分:
// Example structure of moltbot.json
{
"agents": {
"defaults": {
// 默认 Agent 的配置
},
"list": [
{
"id": "my-special-agent",
// 特定 Agent 的配置
}
]
},
"plugins": {
"enabled": true,
"entries": {
"discord": { "enabled": true, "config": { ... } },
"memory-lancedb": { "enabled": true, "config": { ... } }
}
},
"routing": {
"bindings": [
{
"match": { "channel": "discord", "peer": { "id": "123456789" } },
"agentId": "my-special-agent"
}
]
}
}
agents:定义了所有可用的 Agent 实例。defaults部分为所有 Agent 提供了基础配置,而list中的每个对象则可以覆盖默认配置,定义具有特定身份、模型或 Prompt 的独立 Agent。plugins:管理插件的生命周期。你可以在entries中精细地控制每个插件的启用状态 (enabled) 及其具体配置 (config)。routing:这是实现多 Agent、多渠道服务的关键。bindings数组中的每个对象都定义了一条路由规则,将特定渠道、特定对话(如群组 ID 或用户 ID)的消息match到指定的agentId。
这种设计使得用户无需修改代码,仅通过调整 JSON 配置,就能实现复杂的部署和行为定制,例如:
在公司 Slack 群组中运行一个专业的问答 Agent。
在个人 Telegram 上运行一个轻松幽默的日常助理 Agent。
为特定的项目 Discord 频道配置一个专门用于代码审查的 Agent。
理解 moltbot.json 的结构和作用,是掌握 Moltbot 定制与扩展的第一步。
四、部署模型
Moltbot 提供了多种部署方式以适应不同用户的需求,从简单的本地运行到可靠的云端服务。
本地二进制/Node.js 运行:最直接的方式,适合开发者和希望在个人电脑上运行 Moltbot 的用户。
Docker:官方提供了 Dockerfile,可以方便地将 Moltbot 及其依赖打包成容器镜像,实现环境隔离和快速部署。
云服务 (Fly.io, Railway 等):文档中也包含了在 Fly.io 等 PaaS 平台上部署的指南,适合需要 7x24 小时在线服务的场景。
无论采用何种部署方式,Moltbot 的核心逻辑和配置体系都保持一致,确保了体验的统一性。
通过本章的介绍,我们对 Moltbot 的整体设计有了初步的认识。接下来的章节,我们将深入其内部,逐一拆解记忆系统、Skill 管线等更为复杂的模块。
消息路由与多渠道扩展机制
Moltbot 的强大之处在于其能够同时管理多个 Agent 实例,并将它们无缝地对接到不同的消息平台。这一能力的核心是其精密的消息路由系统和高度可扩展的插件化渠道架构。本章将深入剖析这两个机制,揭示 Moltbot 如何实现从消息的“入口”到 Agent 的“大脑”之间的精准导航。
一、消息路由:从“你是谁”到“谁来答”
当一条消息从任意渠道(如 Slack 或 Telegram)进入 Moltbot 时,系统面临的首要问题是:“这条消息应该由哪个 Agent 来处理?” 解决这个问题的过程,就是消息路由。Moltbot 的路由逻辑由 src/routing/resolve-route.ts 中的 resolveAgentRoute 函数集中处理,其决策过程严格遵循 moltbot.json 中 routing.bindings 的配置。
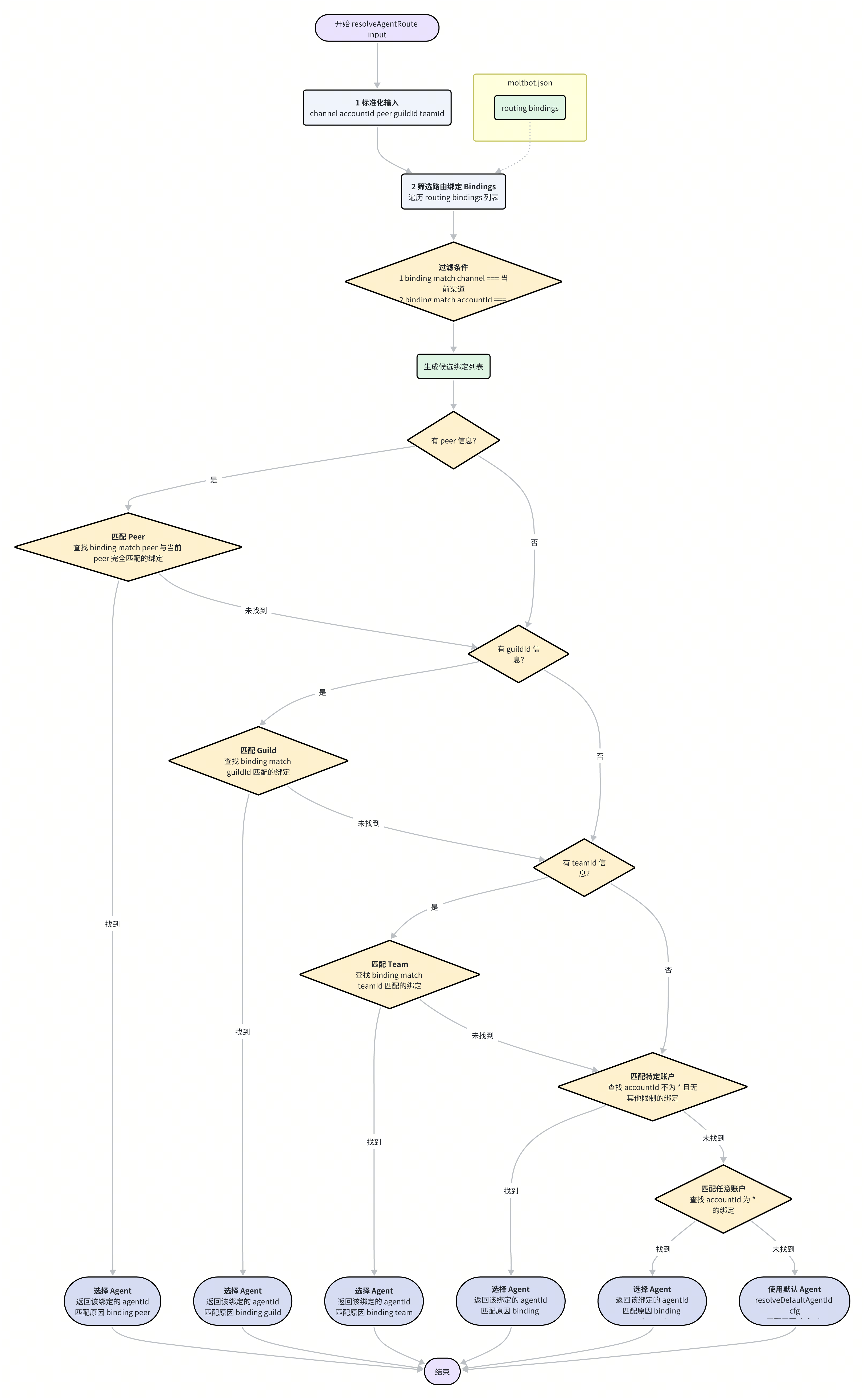
路由决策是一个具有明确优先级的匹配过程,其核心思想是 “最精确的匹配优先”。以下是 resolveAgentRoute 函数的决策步骤:
标准化输入:函数首先会获取并标准化当前消息的所有上下文信息,包括
channel(渠道,如 "discord")、accountId(用户ID)、peer(对话对端,如群组ID或私聊ID)、guildId(Discord 服务器ID) 和teamId(Slack 工作区ID)。筛选候选绑定:系统遍历
moltbot.json中routing.bindings数组的每一条规则。一个绑定规则通常包含match(匹配条件)和agentId(目标 Agent)两部分。只有match.channel与当前消息渠道匹配,并且match.accountId与当前用户ID匹配(或为通配符*)的规则,才会成为候选规则。
// src/routing/resolve-route.ts
const bindings = listBindings(input.cfg).filter((binding) => {
if (!binding || typeof binding !== "object") return false;
if (!matchesChannel(binding.match, channel)) return false;
return matchesAccountId(binding.match?.accountId, accountId);
});
精确匹配优先:接下来,系统会按照从最具体到最泛化的顺序,在候选绑定中进行查找:
Peer 匹配:首先检查是否有绑定的
match.peer与当前对话的peer(如群聊 ID)完全一致。如果找到,则立即选择其对应的agentId,匹配结束。这是最高优先级的匹配。Guild/Team 匹配:如果 Peer 未匹配成功,系统会接着检查
guildId(Discord) 或teamId(Slack),看是否有规则与当前服务器/工作区匹配。特定账户匹配:如果以上均未匹配,系统会寻找仅按特定
accountId匹配的规则(即accountId不为*且没有其他如peer、guildId的限制)。渠道通配符匹配:若仍未找到,系统会寻找
accountId为*的规则,这相当于为该渠道下的所有用户指定了一个默认 Agent。全局默认:如果所有规则都未能匹配,系统将回退到全局默认的 Agent,其 ID 由
resolveDefaultAgentId(input.cfg)决定。
生成会话(Session):一旦确定了
agentId,系统会调用buildAgentSessionKey函数,为本次交互生成一个唯一的sessionKey。这个 key 综合了agentId、渠道、用户 ID、对话 ID 等信息,确保了即使是同一个 Agent 在不同对话中的上下文也是完全隔离的。
通过这套机制,Moltbot 实现了极其灵活的多 Agent 托管能力。开发者可以通过简单地修改 moltbot.json 文件,就能轻松地将不同的 Agent 指派到不同的工作场景,而无需触及任何核心代码。
二、多渠道扩展:插件化的力量
Moltbot 对多消息平台的支持并非硬编码在核心代码中,而是通过一套完整的插件化系统实现的。每个通信渠道(如 Discord, Slack, Matrix)都是一个独立的插件,位于 extensions/ 目录下。这种设计使得添加对新平台的支持变得异常简单。
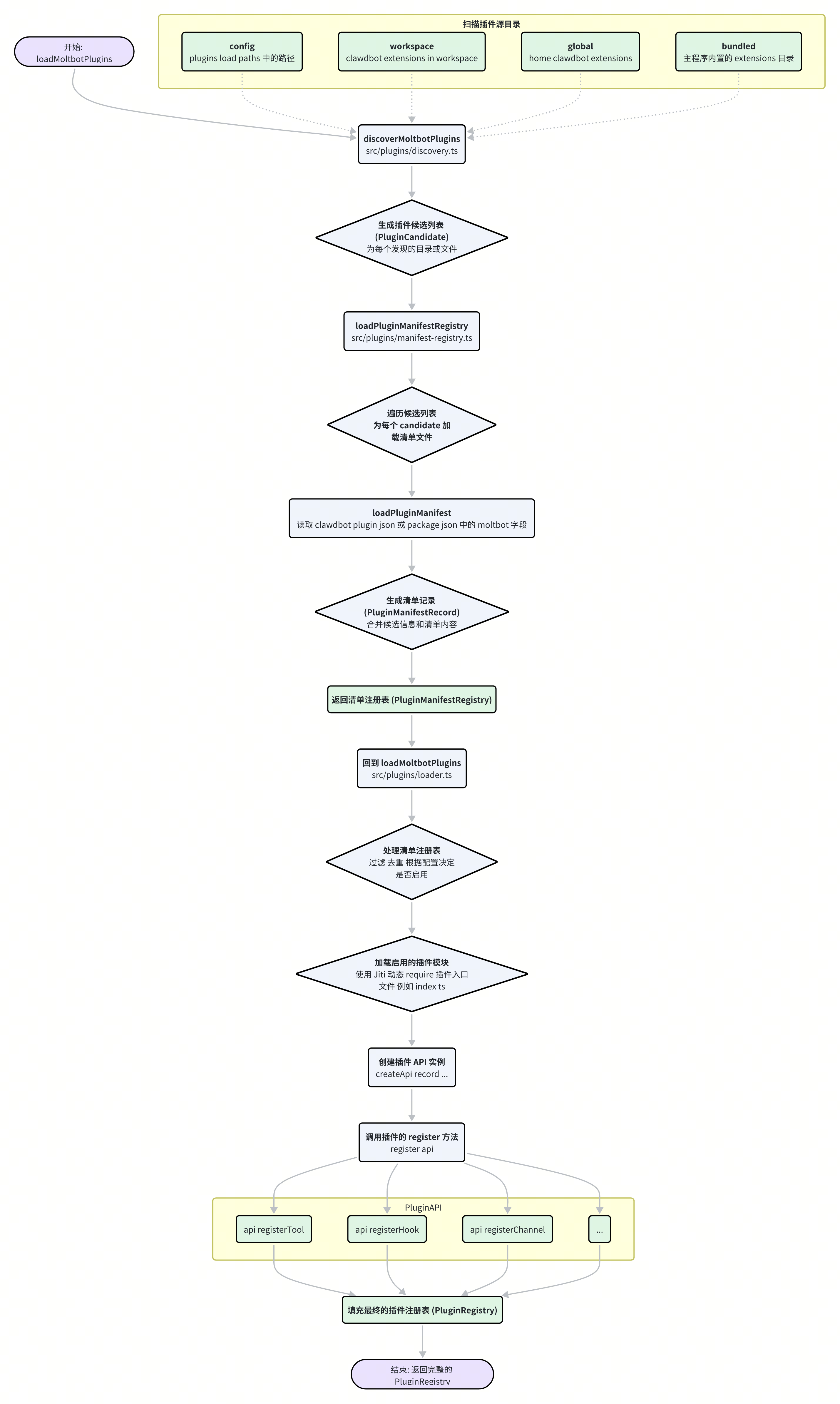
整个插件的生命周期,从发现到最终注册其能力,主要由 src/plugins/loader.ts 和 src/plugins/discovery.ts 协同完成。
1. 插件的发现(Discovery)
discoverMoltbotPlugins 函数负责在文件系统中寻找所有潜在的插件。它会按照固定的优先级扫描以下目录:
config(plugins.load.paths):用户在moltbot.json中明确指定的额外插件路径。workspace:当前工作区下的.clawdbot/extensions目录。global:用户主目录下的~/.clawdbot/extensions。bundled:随 Moltbot 主程序一同分发的内置extensions目录。
在这些目录中,一个插件可以是一个单独的 .ts/.js 文件,也可以是一个包含 index.ts 或 package.json 的目录。discovery 过程会为每个找到的潜在插件生成一个 PluginCandidate 对象,其中包含了插件的源文件路径、来源(origin)等信息。
2. 清单的加载(Manifest Loading)
发现候选插件后,loadPluginManifestRegistry 函数会接手,负责为每个候选插件加载其“身份证明”——清单文件。
清单文件:通常是
clawdbot.plugin.json(或moltbot.plugin.json),它是一个 JSON 文件,定义了插件的id、name、version以及最重要的configSchema(用于验证插件配置)。如果该文件不存在,系统会尝试从package.json的moltbot字段中读取。
// extensions/memory-lancedb/clawdbot.plugin.json
{
"id": "memory-lancedb",
"kind": "memory",
"uiHints": { ... },
"configSchema": { ... }
}
清单记录:加载清单后,系统会生成一个
PluginManifestRecord,它整合了来自文件系统(路径、来源)和清单文件(ID、名称、版本)的所有元数据。
3. 插件的加载与注册(Loading & Registration)
最后,loadMoltbotPlugins 函数 orchestrates 整个过程的最后阶段:
过滤与启用:根据
moltbot.json中的plugins.allow、plugins.deny列表以及plugins.entries.<i>.enabled配置,决定哪些插件应该被加载。动态加载模块:对于启用的插件,Moltbot 使用
jiti这个库来动态地require()插件的入口文件(如index.ts)。Jiti 的一个关键作用是可以在运行时对 TypeScript 文件进行即时编译,从而无需预先构建。它还通过alias配置,将clawdbot/plugin-sdk指向正确的实现,解决了插件在开发和运行两种模式下的依赖问题。
// src/plugins/loader.ts
const jiti = createJiti(import.meta.url, {
interopDefault: true,
// ...
alias: {
"clawdbot/plugin-sdk": pluginSdkAlias,
"moltbot/plugin-sdk": pluginSdkAlias,
},
});
// ...
mod = jiti(candidate.source) as MoltbotPluginModule;
执行
register方法:加载模块后,系统会调用其导出的register(或activate) 方法。这个方法会接收一个api对象作为参数。注册能力:插件通过调用
api对象上的方法,将自己的能力“注册”到 Moltbot 核心中。例如,一个渠道插件会调用api.registerChannel(),一个提供新工具的插件会调用api.registerTool()。
// extensions/memory-core/index.ts
const memoryCorePlugin = {
id: "memory-core",
// ...
register(api: MoltbotPluginApi) {
api.registerTool(
(ctx) => {
// ...
return [memorySearchTool, memoryGetTool];
},
{ names: ["memory_search", "memory_get"] },
);
// ...
},
};
通过这套“发现-加载-注册”的插件化流程,Moltbot 将核心框架与具体的功能实现完全解耦。无论是添加一个新的消息平台,还是引入一种新的记忆存储方式,开发者都可以通过编写一个独立的插件来完成,而无需改动 Moltgbot 的主干代码,这极大地增强了系统的可维护性和扩展性。
记忆系统(一):核心架构与存储引擎
Moltbot 的“智能”很大程度上源于其强大的长期记忆能力。它能够跨越单次对话的局限,记住用户的偏好、过去的决策和重要的上下文信息。这种能力的实现,依赖于一个设计精巧、可插拔的记忆系统。本章将深入其核心,剖析其架构设计、存储引擎的选择,以及两种主要的实现方式:内置的 memory-core 和作为插件的 memory-lancedb。
一、记忆系统的核心协调者:MemoryIndexManager
Moltbot 记忆系统的心脏是 MemoryIndexManager 类,定义于 src/memory/manager.ts。它像一位总调度官,负责协调记忆的整个生命周期:从数据的读取、处理,到 Embedding 的生成、存储,再到最终的检索。
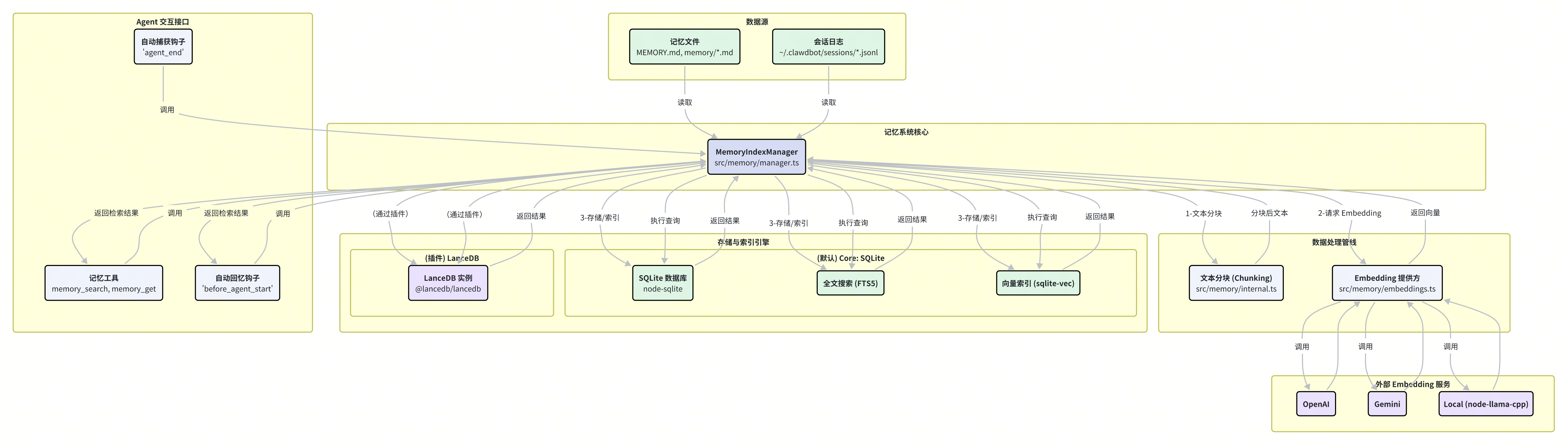
MemoryIndexManager 的核心职责包括:
数据源管理:监控并读取所有被定义为记忆来源的文件,主要包括工作区根目录下的
MEMORY.md、memory/目录下的所有 Markdown 文件,以及(当启用时)~/.clawdbot/sessions/目录下的用户对话历史记录。处理管线协调:将读取到的文本内容送入处理管线,依次进行分块(Chunking)和向量化(Embedding)。
存储与索引:将处理好的文本块及其对应的向量存入后端存储引擎,并建立必要的索引(如全文搜索索引和向量索引)以备快速检索。
查询接口:向上层(如 Agent 工具或自动回忆钩子)提供统一的
search方法,屏蔽底层存储和检索的复杂性。缓存管理:内置了一个 Embedding 缓存机制(
embedding_cache表),避免对相同文本内容的重复计算,节约了成本和时间。同步与刷新:管理记忆索引的更新策略,可以配置为在程序启动、会话开始、执行搜索前或文件发生变化时自动同步索引。
MemoryIndexManager 的设计体现了典型的“关注点分离”原则。它将“数据从哪里来”(数据源)、“数据如何处理”(处理管线)和“数据存到哪里去”(存储引擎)这几个问题解耦,使得每个部分都可以独立地演进和替换。
二、存储引擎:SQLite 的基石作用
与人们通常设想的、需要依赖大型专用向量数据库不同,Moltbot 的默认记忆系统 (memory-core) 精巧地选择了一个极为普遍和轻量级的数据库作为其基石——SQLite。
这个选择体现了其作为个人助理框架的设计哲学:易于部署、资源占用低、无需复杂运维。通过 node-sqlite 这个库,Moltbot 直接在本地文件系统上创建和管理一个 .sqlite 文件,作为所有记忆数据的家。
数据库 Schema 设计
为了支持复杂的记忆功能,Moltbot 在 SQLite 中设计了几个关键的表,其 Schema 定义在 src/memory/memory-schema.ts 中。
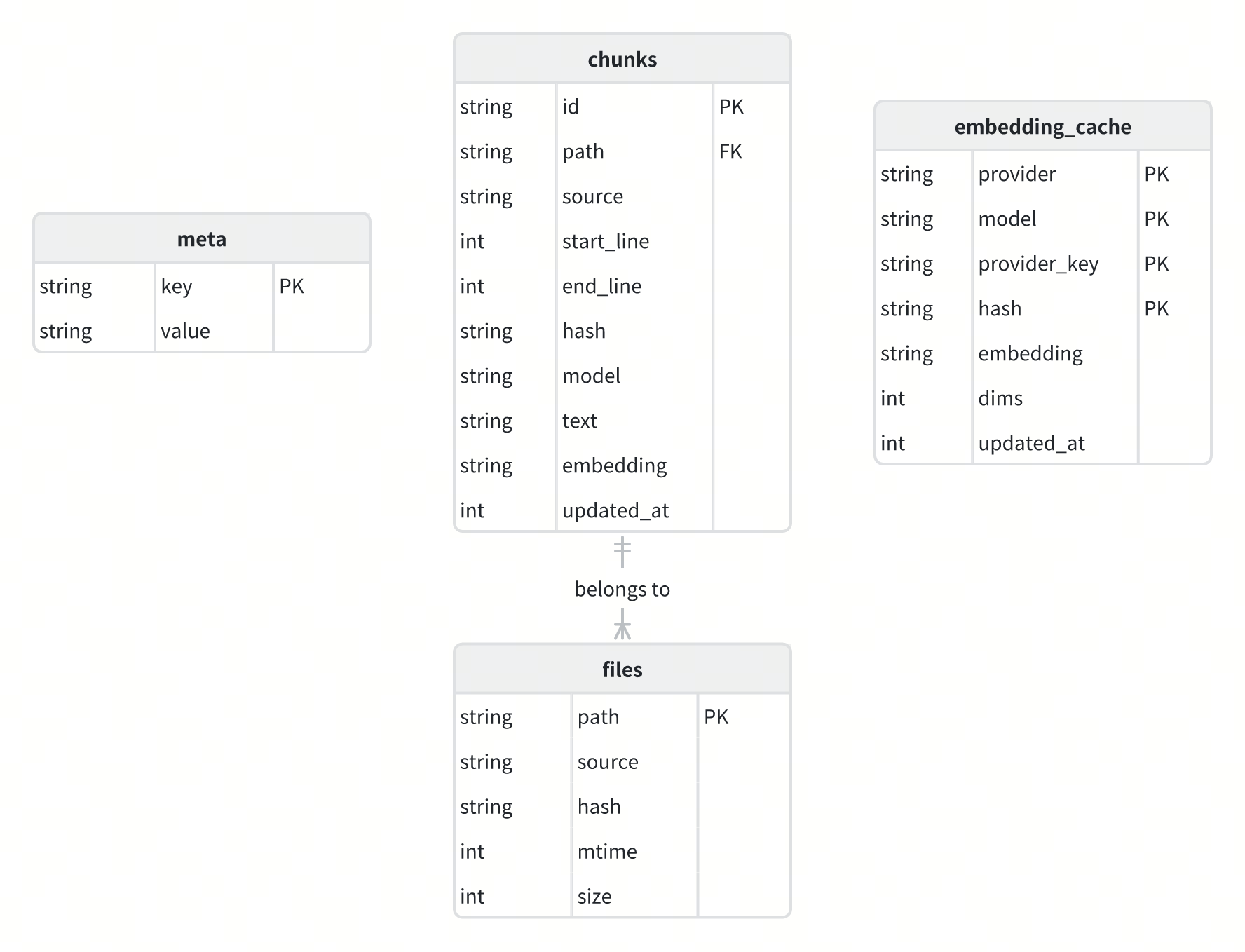
files表:记录了所有被索引的源文件的元信息。path: 文件相对于工作区的路径(主键)。hash: 文件内容的 SHA256 哈希值,用于快速判断文件是否变更。mtime: 文件的最后修改时间。size: 文件大小。
chunks表:存储了从源文件中分割出来的文本块及其 Embedding。这是记忆检索的核心表。id: 文本块的唯一 ID。path: 所属源文件的路径,与files表关联。start_line,end_line: 该文本块在源文件中的起止行号。hash: 文本块内容的哈希值。text: 原始文本内容。embedding: 文本内容的向量表示,以 JSON 字符串形式存储。
embedding_cache表:用于缓存文本哈希到 Embedding 向量的映射,避免重复计算。meta表:存储索引的元数据,如使用的模型、分块大小等,用于确保索引版本的一致性。
向量检索的实现:sqlite-vec
原生 SQLite 并不支持向量检索。为了解决这个问题,Moltbot 引入了一个名为 sqlite-vec 的 SQLite 扩展。这个扩展为 SQLite 赋予了近似最近邻(ANN)搜索的能力,使得可以直接在数据库中进行高效的向量相似度计算。
MemoryIndexManager 通过 loadSqliteVecExtension 函数动态加载 sqlite-vec 扩展,并通过 CREATE VIRTUAL TABLE ... USING vec0(...) 语法创建一个虚拟表(chunks_vec),专门用于存储和查询向量数据。
// src/memory/manager.ts L682
this.db.exec(
`CREATE VIRTUAL TABLE IF NOT EXISTS ${VECTOR_TABLE} USING vec0(\n` +
` id TEXT PRIMARY KEY,\n` +
` embedding FLOAT[${dimensions}]\n` +
`)`,
);
这种将向量能力直接构建于 SQLite 之上的方法,使得 Moltbot 的核心记忆功能无需任何外部数据库依赖,极大地简化了用户的设置和维护成本。
三、两种实现:memory-core vs memory-lancedb
Moltbot 的记忆系统提供了两种实现方式,体现了其“内核+插件”的可扩展思想。
memory-core(内置核心)实现位置:
extensions/memory-core/index.ts性质:作为 Moltbot 的内置插件,默认启用。
职责:它本身不包含复杂的记忆逻辑,其主要作用是作为“适配器”,将
MemoryIndexManager的能力通过api.registerTool和api.registerCli暴露为 Agent 可用的工具(memory_search,memory_get)和命令行接口(moltbot memory ...)。依赖:直接依赖于
src/memory/manager.ts的核心实现,使用上述的 SQLite +sqlite-vec作为后端。
memory-lancedb(LanceDB 插件)实现位置:
extensions/memory-lancedb/index.ts性质:一个可选插件,如果启用,它将通过“插件槽(Slot)”机制取代
memory-core。职责:它提供了记忆系统的另一套完整实现。它没有使用内置的
MemoryIndexManager,而是自己实现了一个MemoryDB类,使用LanceDB这个专为 AI 设计的开源向量数据库作为后端。优势:
LanceDB提供了比sqlite-vec更强大和专业的向量存储与检索功能,例如更丰富的索引类型和查询优化,适合对记忆系统性能有更高要求的场景。扩展功能:
memory-lancedb插件还实现了完整的自动回忆(Auto-Recall)和自动捕获(Auto-Capture)逻辑,这是memory-core中未包含的。它通过注册before_agent_start和agent_end钩子,实现了在对话前后自动处理记忆的能力。
// extensions/memory-lancedb/index.ts
if (cfg.autoRecall) {
api.on("before_agent_start", async (event) => {
// ... search and inject memories
});
}
if (cfg.autoCapture) {
api.on("agent_end", async (event) => {
// ... analyze and store memories
});
}
插件槽(Plugin Slot)机制
Moltbot 如何确保 memory-core 和 memory-lancedb 不会同时运行呢?答案是插件槽(Plugin Slot)机制。
在 src/plugins/slots.ts 中定义了不同类型的插件槽,其中就包括 \"memory\" 槽。系统规定,对于同一类型的槽,只能有一个插件处于激活状态。用户可以在 moltbot.json 中通过 plugins.slots.memory 字段明确指定使用哪个插件来填充这个槽。
{
"plugins": {
"slots": {
"memory": "memory-lancedb"
},
"entries": {
"memory-lancedb": { "enabled": true, "config": { ... } }
}
}
}
当 loadMoltbotPlugins 加载插件时,resolveMemorySlotDecision 函数会检查每个插件的 kind 是否为 \"memory\",并根据 slot 的配置决定是否启用它。如果用户指定了 memory-lancedb,那么 memory-core 就会被自动禁用,从而实现了两种记忆引擎的平滑切换。
总结来说,Moltbot 的记忆系统通过一个通用的核心管理器 (MemoryIndexManager) 和一个基于 SQLite 的轻量级默认实现,提供了开箱即用的长期记忆能力。同时,通过插件化和槽机制,它又允许用户无缝替换为如 LanceDB 这样更专业的向量数据库,以满足不同场景下的性能和功能需求。这种兼具易用性和可扩展性的架构设计,是 Moltbot 的一大亮点。
记忆系统(二):索引、检索与数据流
在了解了 Moltbot 记忆系统的核心架构和存储引擎之后,本章我们将深入其内部的数据流,详细探讨两个关键过程:索引(Indexing)——如何将非结构化的文本数据转化为可检索的知识;以及 检索(Retrieval)——如何在需要时高效、精准地从知识库中找出相关信息。
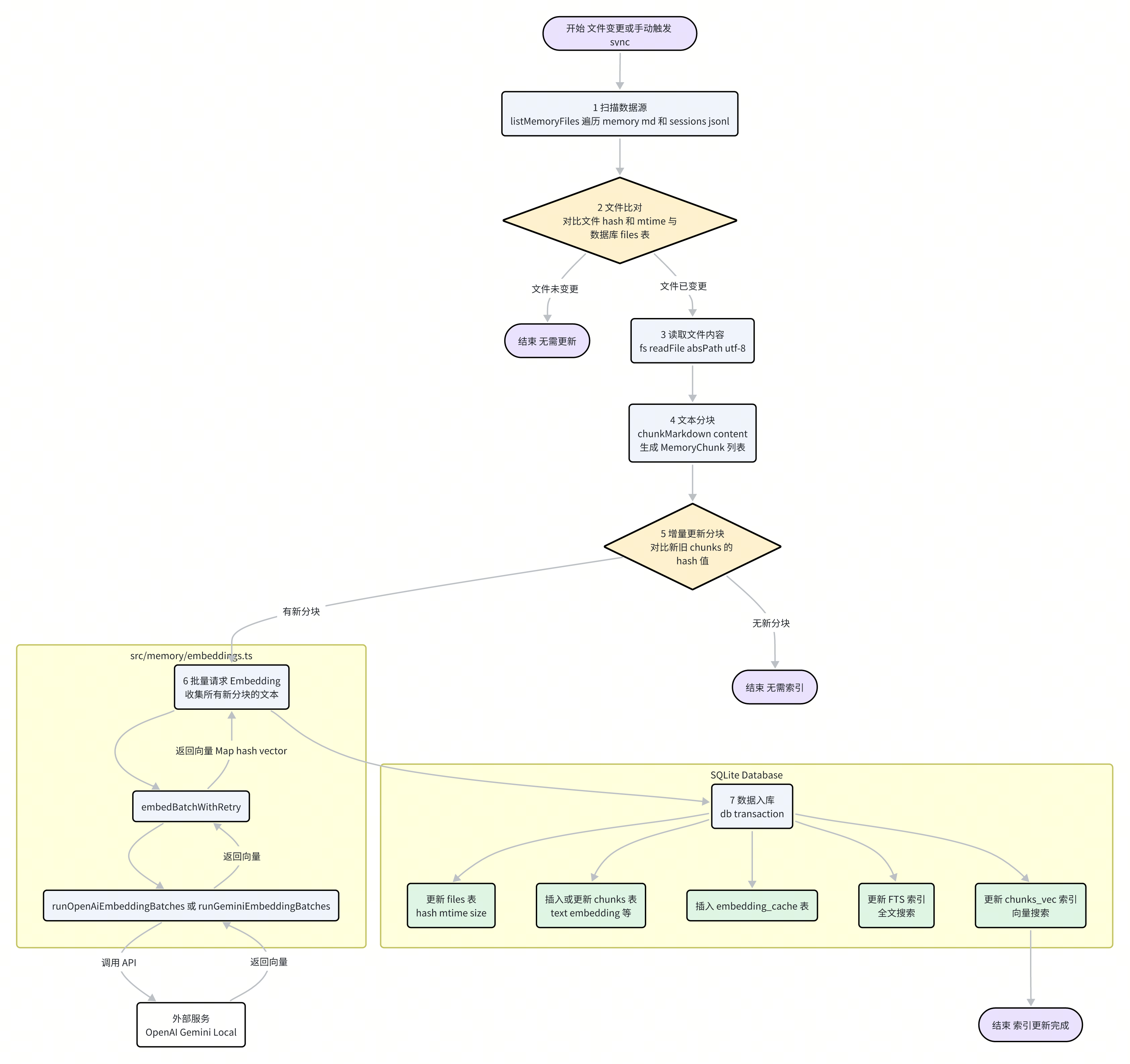
整个索引流程可以分解为以下几个核心步骤:
触发与扫描:索引流程由文件变更(通过
chokidar监听)或手动调用manager.sync()触发。一旦触发,listMemoryFiles函数会扫描所有配置的数据源路径(如memory/*.md),生成一个待处理的文件列表。变更检测:为了避免不必要的重复工作,系统会首先将待处理文件的哈希值和修改时间与数据库
files表中记录的值进行比较。只有内容发生变化(哈希值不同)或被更新过的文件,才会进入下一步。文本分块 (Chunking):对于需要更新的文件,系统会读取其全部内容,并调用
chunkMarkdown函数(位于src/memory/internal.ts)进行分块。该函数并非简单地按固定长度切分,而是会考虑 Markdown 的段落结构,并引入重叠(Overlap)机制,以保证上下文的完整性。分块的大小由配置中的chunking.tokens和chunking.overlap控制。
// src/memory/internal.ts
export function chunkMarkdown(
content: string,
chunking: { tokens: number; overlap: number },
): MemoryChunk[] {
// ... 实现将长文本分割为带有重叠部分的小块
}
增量更新决策:分块后,系统会计算每个新文本块的哈希值,并与
chunks表中已存在的记录进行对比。只有哈希值不存在(即全新的或内容已修改)的文本块,才会被送去生成 Embedding。批量 Embedding:这是索引流程中最耗时和耗费资源的一步。
MemoryIndexManager会收集所有需要处理的新文本块,并调用embedBatchWithRetry方法。该方法会根据配置的provider(如 "openai" 或 "gemini"),选择相应的批量处理函数,如runOpenAiEmbeddingBatches(src/memory/batch-openai.ts)。这些函数会将成百上千个文本块打包成单个或少数几个 API 请求,极大地提升了效率并降低了成本。
// src/memory/batch-openai.ts
export async function runOpenAiEmbeddingBatches(params: {
openAi: OpenAiEmbeddingClient;
requests: OpenAiBatchRequest[];
// ...
}): Promise<Map<string, number[]>> {
// ... 实现对 OpenAI Batch API 的调用
}
数据入库:获取到文本块对应的向量后,所有更新操作会在一个数据库事务(
db.transaction(...))中完成,以确保数据的一致性:更新
files表中文件的元数据。将新的文本块及其向量插入或更新到
chunks表。如果使用了 FTS,则同步更新全文搜索索引。
如果使用了
sqlite-vec,则同步更新向量索引。将新生成的 Embedding 存入
embedding_cache表,以备未来复用。
通过这套精密的增量索引机制,Moltbot 确保了其记忆库在高效运作的同时,始终保持着最新状态。
二、检索机制:精准定位信息的艺术
当 Agent 需要“回忆”时,记忆系统必须能从海量信息中快速、准确地找出最相关的内容。Moltbot 并没有简单地依赖单一的检索技术,而是采用了一种更先进的混合检索(Hybrid Search)策略,结合了向量搜索和传统关键词搜索的优点。
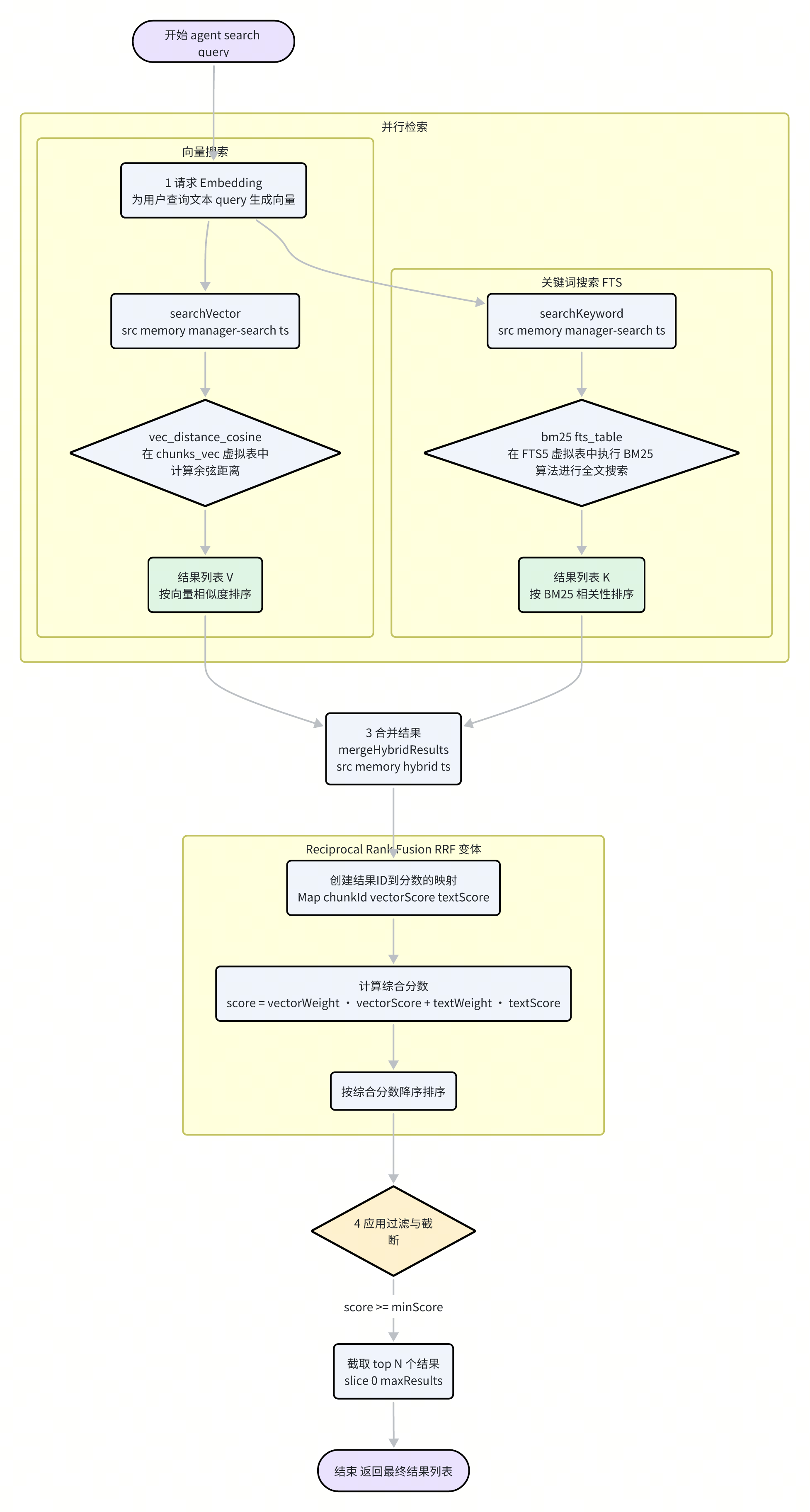
1. 并行检索
当 MemoryIndexManager 的 search 方法被调用时,它会并行执行两种不同类型的查询:
向量搜索 (Vector Search):由
searchVector函数(src/memory/manager-search.ts)执行。首先,用户的查询文本
query会被同一个 Embedding 模型转化为查询向量queryVec。然后,系统使用
sqlite-vec提供的vec_distance_cosine函数,在chunks_vec虚拟表中计算查询向量与所有存储向量之间的余弦距离。距离越小,代表语义越相似。返回按向量相似度得分(1 - distance)排序的 top-N 结果。
关键词搜索 (Keyword Search / FTS):由
searchKeyword函数执行。用户的查询文本
query会被buildFtsQuery函数处理,提取出关键词并构建成 FTS5 引擎可以理解的查询语句(如\"keyword1\" AND \"keyword2\")。系统在
chunks_fts这个全文搜索虚拟表上执行查询,利用 BM25 算法计算每个文本块与查询的相关性分数。返回按 BM25 相关性得分排序的 top-N 结果。
2. 结果融合:Reciprocal Rank Fusion
两种检索方式各有优劣:向量搜索擅长理解语义和概念,但可能对特定关键词不敏感;关键词搜索能精准匹配术语,但无法理解同义词或相关概念。为了取长补短,Moltbot 采用了一种名为倒数排序融合(Reciprocal Rank Fusion, RRF)的策略来合并这两组结果。
mergeHybridResults 函数(位于 src/memory/hybrid.ts)实现了这一逻辑:
创建结果并集:函数首先创建一个包含所有两种搜索结果中出现过的文本块 ID 的集合。
计算综合分数:对于每个唯一的文本块,系统会根据其在向量搜索结果列表和关键词搜索结果列表中的排名,赋予其一个综合分数。Moltbot 使用了一种简化的加权融合策略,而非经典的 RRF
1/(k+rank)公式:
// src/memory/hybrid.ts (示意逻辑)
const merged = Array.from(byId.values()).map((entry) => {
const score = params.vectorWeight * entry.vectorScore + params.textWeight * entry.textScore;
return {
// ...
score,
// ...
};
});
这里的 vectorWeight 和 textWeight 是可配置的权重(默认为 0.7 和 0.3),允许开发者根据场景调整两种搜索方式的相对重要性。
最终排序与过滤:所有文本块根据计算出的综合分数进行降序排序。最后,系统会应用
minScore阈值过滤掉相关性过低的结果,并截取maxResults指定数量的最高分结果,作为最终的记忆返回给 Agent。
通过这种智能的混合检索策略,Moltbot 能够在各种查询场景下都表现出色。无论是用户提出一个包含特定术语的精确问题,还是一个宽泛的概念性询问,记忆系统都能高效地召回最相关的知识片段,为 Agent 的高质量回复提供了坚实的基础。
记忆系统(三):自动捕获、回忆与会话关联
Moltbot 记忆系统的精髓不仅在于其拥有存储和检索信息的能力,更在于它能主动地、智能地在对话的自然流程中运用这些能力。这种主动性体现在两个关键机制上:自动回忆(Auto-Recall)和自动捕获(Auto-Capture)。本章将聚焦于这两个自动化流程,并探讨记忆系统如何与更广泛的会话(Session)历史机关联,形成一个完整的记忆闭环。
这两个自动化功能主要由 memory-lancedb 插件提供,通过注册 Moltbot 的生命周期钩子(Hooks)来实现。
一、自动回忆(Auto-Recall):让 Agent “记起”过去
“自动回忆”机制确保了 Agent 在开始一次新的推理之前,能够自动地“回想”起与当前话题相关的历史信息,从而做出更具上下文感知能力的响应。这一过程在 before_agent_start 钩子中触发。
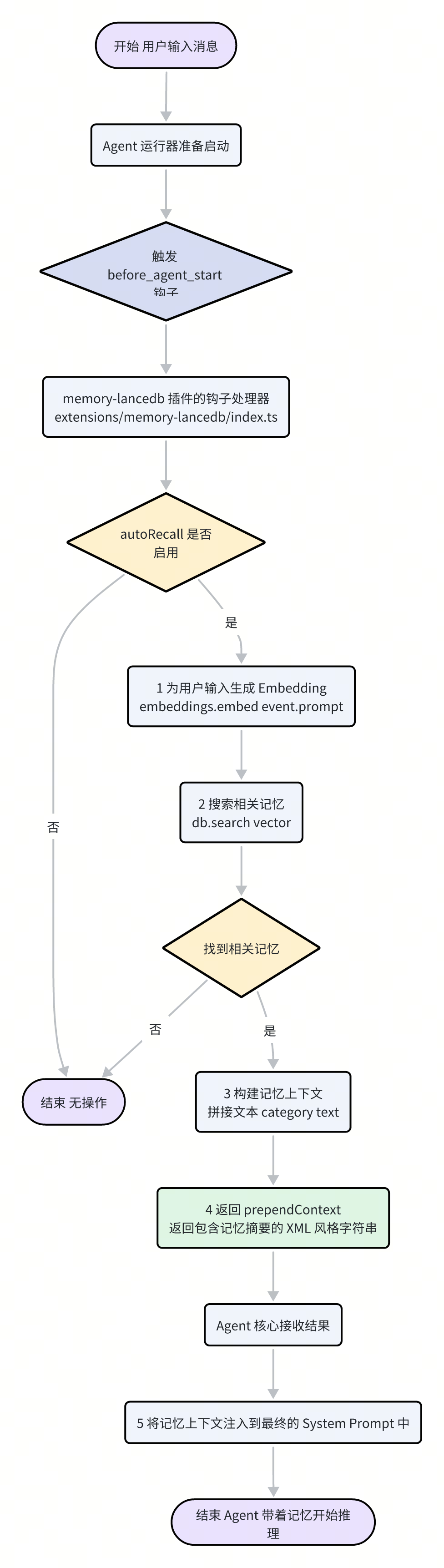
当用户发送一条新消息,Agent 准备开始处理时,流程如下:
钩子触发:
agent-runner在调用 LLM 之前,会触发before_agent_start事件。插件响应:
memory-lancedb插件监听此事件。如果其配置autoRecall为true,处理器便会启动。查询与检索:插件获取用户的当前输入(
event.prompt),为其生成 Embedding 向量,并调用db.search()在记忆库中进行一次快速的相关性搜索。
// extensions/memory-lancedb/index.ts
api.on("before_agent_start", async (event) => {
if (!event.prompt || event.prompt.length < 5) return;
try {
const vector = await embeddings.embed(event.prompt);
const results = await db.search(vector, 3, 0.3);
// ...
}
});
构建上下文:如果找到了足够相关的记忆(默认最多 3 条,相似度得分大于 0.3),插件会将这些记忆的文本内容格式化成一个简洁的列表。
注入上下文:最关键的一步,插件将格式化后的记忆列表包装在一个 XML 风格的标签(
<relevant-memories>...</relevant-memories>)中,并通过prependContext字段返回给 Agent 核心。
// extensions/memory-lancedb/index.ts
return {
prependContext: `<relevant-memories>
The following memories may be relevant to this conversation:${memoryContext}</relevant-memories>`,};```
影响 Prompt:Agent 核心在构建最终的系统提示词(System Prompt)时,会将这个
prependContext的内容插入到 Prompt 的最前面。这样,当 LLM 开始推理时,它看到的第一段信息就是这些高度相关的历史记忆,仿佛 Agent 在开口说话前,就已经“回忆”了一遍过往。
这个无缝的自动化流程,使得 Moltbot 的对话不再是孤立的、一次性的,而是建立在持续积累的知识基础之上,表现得更像一个拥有连贯记忆的智慧体。
二、自动捕获(Auto-Capture):从对话中学习
如果说“自动回忆”是记忆的“读取”操作,那么“自动捕获”就是记忆的“写入”操作。它让 Moltbot 能够从与用户的对话中不断学习和成长,自动识别并保存那些未来可能用得上的重要信息。该机制在 agent_end 钩子中触发。
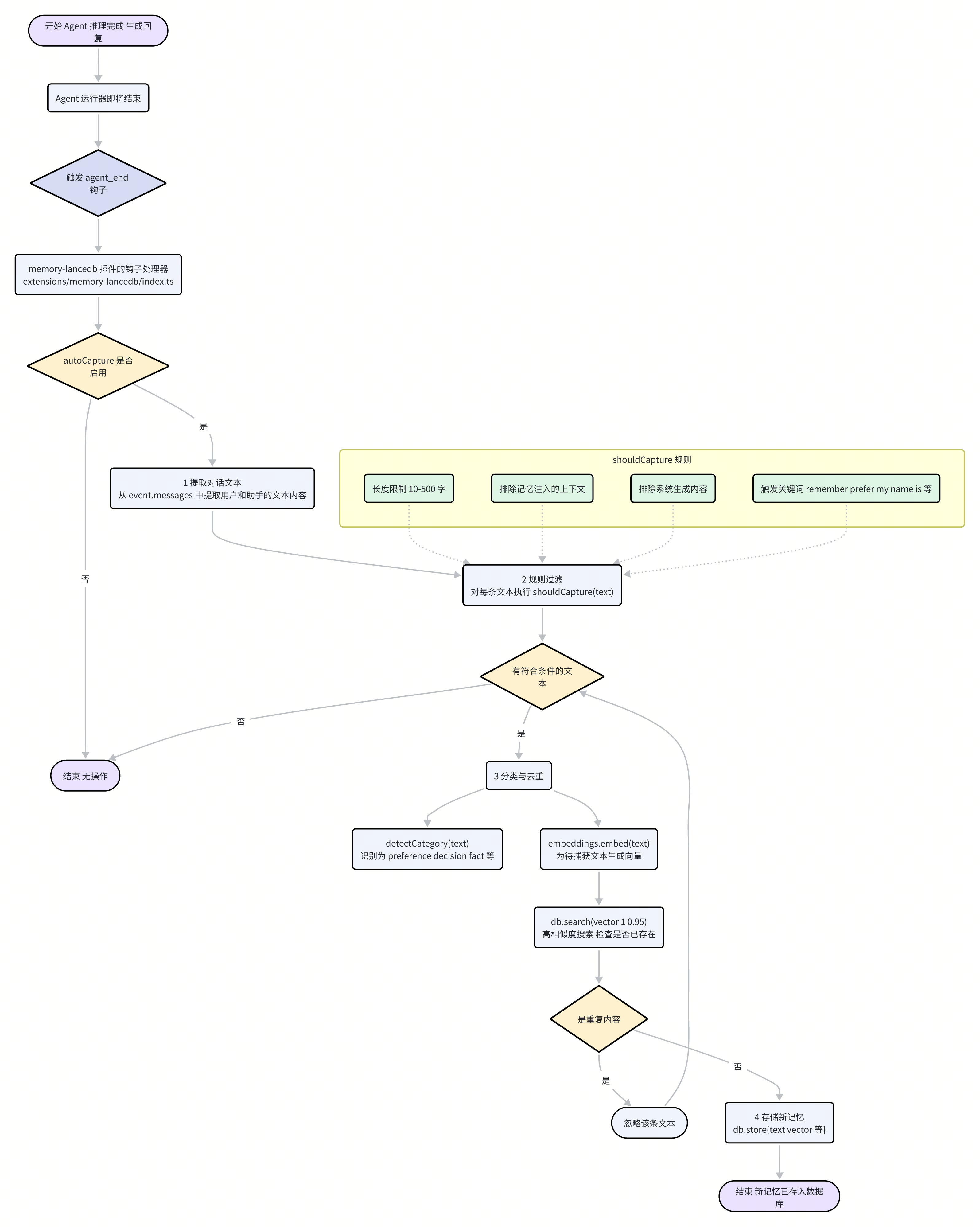
在 Agent 完成一次成功的推理,并生成回复后,流程如下:
钩子触发:
agent-runner在对话回合结束时,触发agent_end事件。插件响应:
memory-lancedb插件监听此事件。如果autoCapture配置为true,处理器启动。内容提取与过滤:插件首先从事件的
messages负载中提取所有由用户和助手产生的文本。然后,每一段文本都会经过shouldCapture(text)函数的严格筛选。shouldCapture定义了一系列启发式规则,用于判断一段文本是否包含“值得记忆”的信息。这些规则非常实用,例如:长度限制:太短或太长的文本通常信息量有限。
排除自身注入:包含
<relevant-memories>标签的文本会被跳过,以防“记忆”自己的“回忆”。关键词触发:包含 “remember”, “my name is”, “I prefer”, “we decided” 等关键词的句子,有很大概率是需要被记住的。
实体识别:简单的正则表达式用于识别电话号码、邮箱地址等实体。
分类与去重:对于通过了筛选的文本,系统会进一步处理:
分类:
detectCategory(text)函数会根据文本中的关键词(如 "like", "decided"),将其粗略地分类为 "preference"(偏好)、"decision"(决定)、"fact"(事实)等。去重:为了避免存储大量冗余信息,系统会为待捕获的文本生成向量,并在数据库中进行一次高相似度(阈值为 0.95)的搜索。如果发现已存在非常相似的记忆,则放弃本次存入。
存储新记忆:对于全新的、有价值的信息,
db.store()方法被调用,将文本、向量、类别等信息一同写入数据库,形成一条新的记忆。
通过这套“捕获-过滤-去重-存储”的自动化流程,Moltbot 能够像海绵一样,在与用户的每一次互动中,悄无声息地吸收和积累知识。
三、记忆的边界:会话历史(Session)的关联
虽然 MEMORY.md 和 memory/ 目录是记忆的主要来源,但 Moltbot 的记忆系统还有一个更广阔的数据源:完整的会话历史记录。这些记录以 .jsonl 格式存储在 ~/.clawdbot/agents/<agentId>/sessions/ 目录下,包含了每一次对话的完整细节。
在 memorySearch 的配置中,可以指定 sources 数组来决定记忆搜索的范围。
"memorySearch": {
"sources": ["memory", "sessions"]
}
当 sessions 被包含在 sources 中时,MemoryIndexManager 的 sync 过程就会将这些会话日志也纳入索引范围。syncSessionFiles 函数会读取这些 .jsonl 文件,提取其中的用户和助手对话,然后将它们同样送入分块和 Embedding 的流程中。
此外,为了更高效地处理增量更新的会话日志,MemoryIndexManager 还实现了一套精巧的 delta 更新机制。
监听更新:通过
onSessionTranscriptUpdate事件,管理器可以实时获知哪个会话文件发生了变化。增量阈值:在配置中可以定义
sync.sessions.deltaBytes和sync.sessions.deltaMessages两个阈值。
触发同步:管理器会累积每个会话文件的变更量(字节数和消息数)。只有当变更量超过设定的阈值时,才会真正触发一次对该会话文件的增量索引。
// src/auto-reply/reply/memory-flush.ts
// 注意:虽然这个文件叫 memory-flush,但 shouldRunMemoryFlush 逻辑本身是通用的
// 其核心逻辑在 manager.ts 的 processSessionDeltaBatch 中被调用
function shouldRunMemoryFlush(...) {
// ... 计算是否达到阈值
}
这个机制巧妙地平衡了数据的实时性和系统的性能。它确保了最近的对话可以很快被“记住”并用于检索,同时又避免了因过于频繁地处理大型日志文件而带来的性能开销。
综上所述,Moltbot 的记忆系统不仅是一个被动的数据库,更是一个与 Agent 的生命周期深度整合、具备主动学习和回忆能力的动态系统。通过巧妙的钩子机制、实用的启发式规则以及与会话历史的智能关联,Moltbot 成功地为其核心 Agent 赋予了强大而连贯的长期记忆。
Skill 管线(一):Skill 的发现与加载
如果说“记忆系统”是 Moltbot 的“大脑”,那么“Skill 管线”就是它的“双手”。Skill 定义了 Agent 能做什么、如何做。它是一套标准化的机制,让 Agent 能够理解并使用外部工具。本章将深入探讨 Skill 管线的第一个阶段:Moltbot 是如何发现、加载并理解散落在各处的 Skills 的。
一、什么是 Skill?
在 Moltbot 的世界里,一个 Skill 本质上非常简单:它是一个包含 SKILL.md 文件的目录。
SKILL.md:这是 Skill 的核心。它是一个 Markdown 文件,但其头部包含一段 YAML 格式的“前言”(Frontmatter),用于定义 Skill 的元数据。Markdown 的正文部分则是写给 LLM 看的“说明书”,用自然语言描述了这个 Skill 的用途、如何调用以及需要注意的事项。
一个典型的 Skill 目录结构如下:
skills/
└── weather/
├── SKILL.md # 核心定义文件
└── scripts/
└── get_weather.py # Skill 可能用到的脚本
SKILL.md 的 Frontmatter 示例:
---
name: weather
description: Get the current weather for a given location.
metadata:
moltbot:
emoji: "🌦️"
requires:
bins: ["python3"]
---
# Weather Skill
This skill allows you to get the current weather conditions for any city...
从这个简单的结构中,我们可以看出 Skill 设计的两个核心原则:
机器可读 (Frontmatter):提供结构化的元数据,如名称、描述、依赖等,供 Moltbot 系统进行解析和过滤。
模型可读 (Markdown Body):提供自然语言的说明,供 LLM 理解工具的上下文和使用方法。
二、Skill 的发现之旅:来源与优先级
Moltbot 在启动时,会像一个探险家一样,在文件系统的多个预定地点寻找 Skill。这个发现过程有严格的优先级顺序,高优先级的 Skill 会覆盖低优先级的同名 Skill,从而实现了灵活的定制和覆盖。
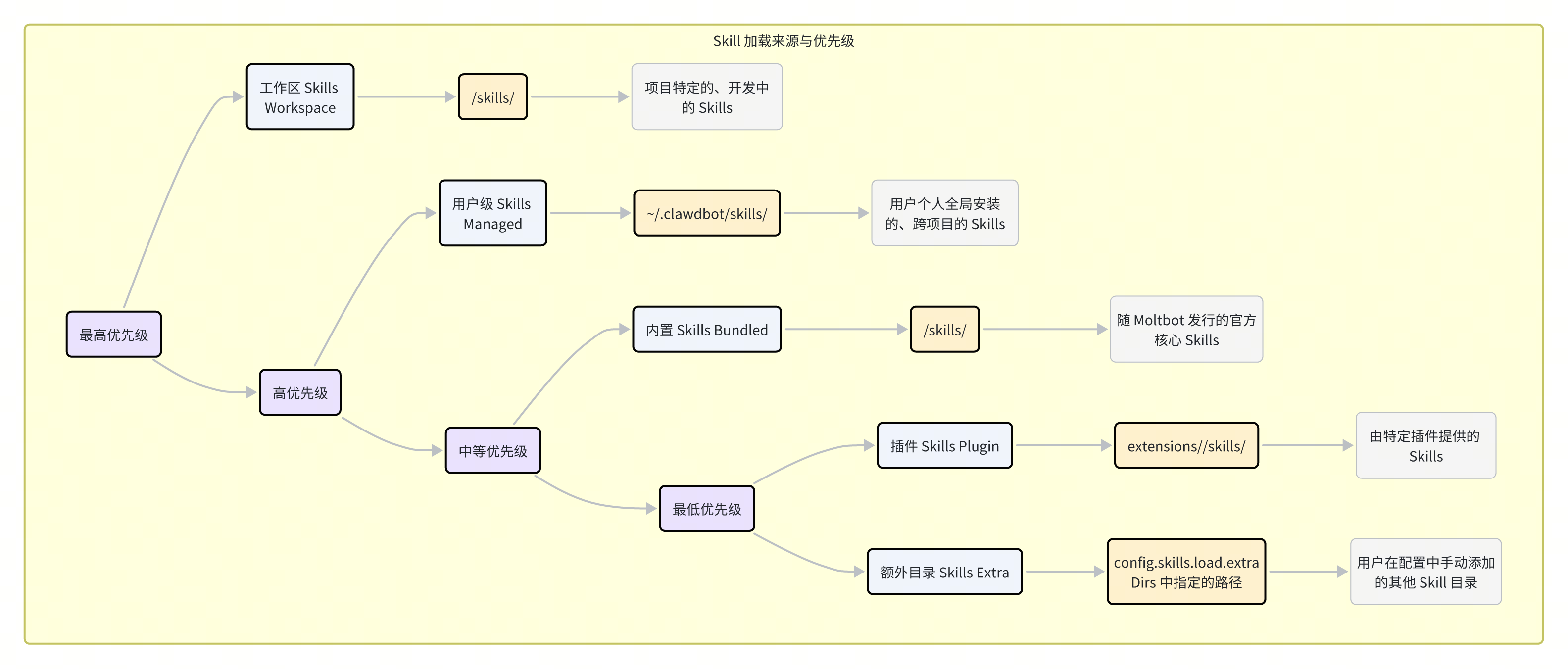
Skill 的加载来源按优先级从低到高排列如下:
插件与额外目录 (Plugin & Extra Skills):
插件 Skills:位于每个插件目录下的
skills/子目录中,如extensions/my-plugin/skills/。它们与插件生命周期绑定,是扩展 Moltbot 功能的首选方式。额外目录:在
moltbot.json中通过skills.load.extraDirs数组指定的任意路径。这为用户组织和共享 Skill 提供了极大的灵活性。
内置 Skills (Bundled Skills):
位于 Moltbot 安装根目录下的
skills/目录。这些是官方提供的、构成 Moltbot 核心能力的 Skill,随程序一同发行。
用户级 Skills (Managed Skills):
位于
~/.clawdbot/skills/。这个目录是为用户准备的“全局” Skill 空间。存放在这里的 Skill 对该用户的所有 Agent 实例都可见,非常适合存放跨项目的、个人常用的自定义 Skill。
工作区 Skills (Workspace Skills):
位于当前 Agent 工作区(Workspace)的
skills/目录下。这是最高优先级的来源,允许开发者针对特定项目覆盖或开发新的 Skill,而不会影响全局或其他项目。
这个分层设计使得用户既能享受到官方提供的便利,又能根据个人需求进行全局定制,还能为特定项目进行深度开发,层次分明,互不干扰。
三、加载流程:从文件到内存对象
Moltbot 将上述发现过程实现在 src/agents/skills/workspace.ts 的 loadSkillEntries 函数中。这个函数是整个 Skill 管线的入口。
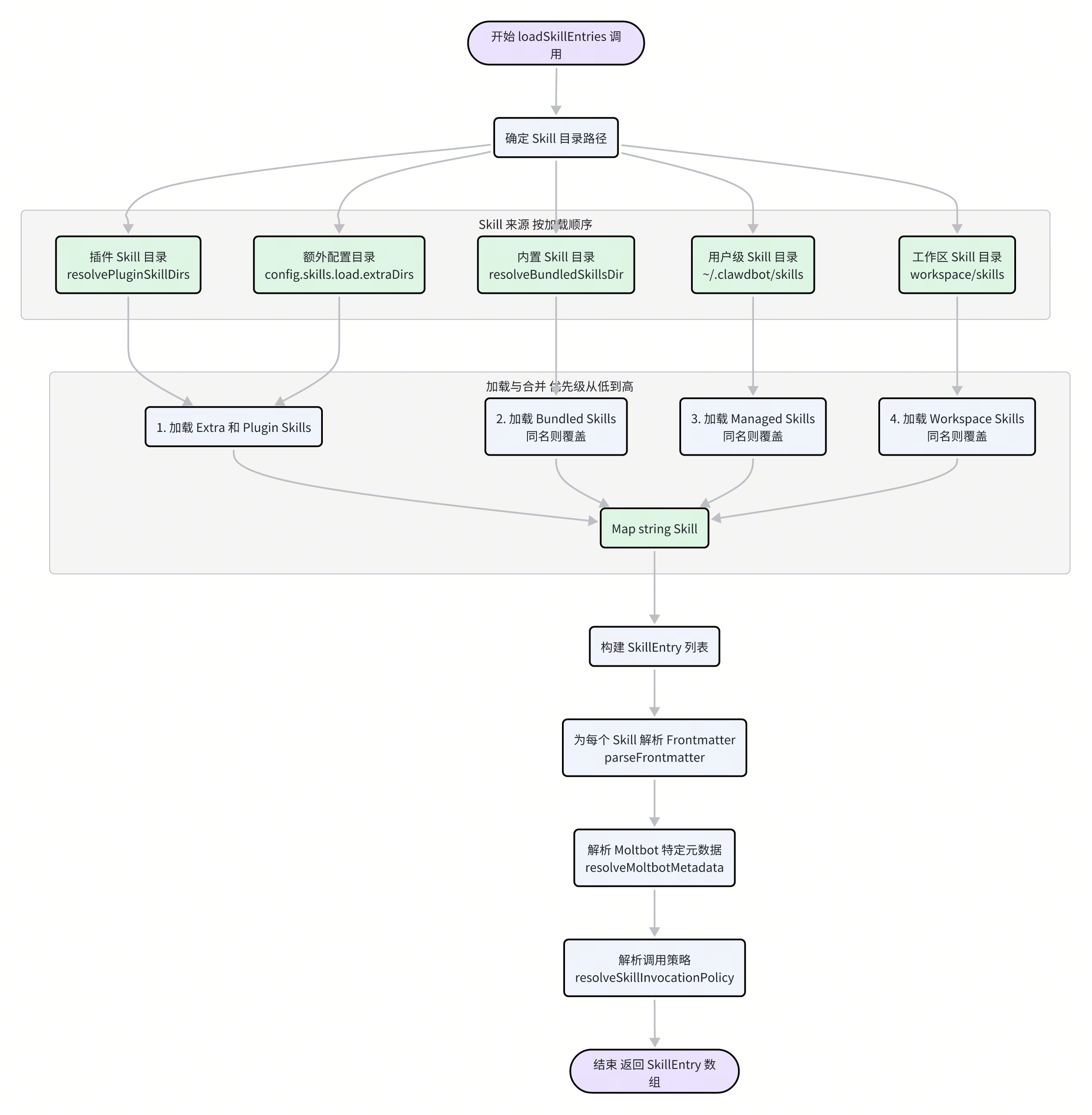
整个加载流程可以分解为以下几个步骤:
确定所有来源路径:函数首先解析出上述所有可能的 Skill 目录路径,包括插件、额外配置、内置、用户级和工作区。
加载原始 Skill 定义:程序使用
@mariozechner/pi-coding-agent包中的loadSkillsFromDir函数,依次遍历这些目录,将找到的SKILL.md文件解析成一个临时的Skill对象列表。按优先级合并:这是一个关键步骤。Moltbot 使用一个
Map<string, Skill>结构,以 Skill 的名称为主键。它按照从低到高的优先级顺序(插件 -> 内置 -> 用户 -> 工作区)依次将 Skill 放入 Map。如果遇到同名的 Skill,后来的(更高优先级的)会自动覆盖前者。// src/agents/skills/workspace.ts const merged = new Map<string, Skill>(); // Precedence: extra < bundled < managed < workspace for (const skill of extraSkills) merged.set(skill.name, skill); for (const skill of bundledSkills) merged.set(skill.name, skill); for (const skill of managedSkills) merged.set(skill.name, skill); for (const skill of workspaceSkills) merged.set(skill.name, skill);最终,这个
mergedMap 中就包含了所有唯一的、按最高优先级选择的 Skill。构建
SkillEntry:合并之后,程序将Skill对象列表转换为更丰富的SkillEntry对象列表。在这个过程中,它会做几件重要的事情:读取并解析 Frontmatter:
parseFrontmatter函数被调用,将SKILL.md文件头部的 YAML 文本解析成一个 JavaScript 对象。解析 Moltbot 元数据:
resolveMoltbotMetadata函数会专门提取 Frontmatter 中metadata.moltbot字段下的内容,这是 Moltbot 进行依赖检查和权限控制的依据。解析调用策略:
resolveSkillInvocationPolicy函数解析userInvocable和disableModelInvocation等字段,确定该 Skill 是否能被用户通过命令直接调用,或是否对 LLM 不可见。
// src/agents/skills/workspace.ts const skillEntries: SkillEntry[] = Array.from(merged.values()).map((skill) => { // ... frontmatter = parseFrontmatter(raw); // ... return { skill, frontmatter, metadata: resolveMoltbotMetadata(frontmatter), invocation: resolveSkillInvocationPolicy(frontmatter), }; });
经过这一系列流程,原本分散在文件系统各处的 SKILL.md 文件,就被转化成了内存中结构化的 SkillEntry 对象数组。这些对象不仅包含了 Skill 的基本信息,还附带了解析好的元数据和调用策略,为后续的过滤、权限检查和 Prompt 构建做好了充分的准备。
Skill 管线(二):可用性过滤与动态刷新
在上一章中,我们了解了 Moltbot 如何从文件系统中发现并加载 Skill。然而,加载 Skill 只是第一步。在它们真正被 Agent 使用之前,还必须经过一系列严格的“审查”,以确保它们在当前环境下是可用、被允许且安全的。此外,Moltbot 还具备动态刷新机制,能够响应 Skill 文件的变化,而无需重启服务。本章将深入探讨这两个核心机制。
一、守门人:Skill 的可用性过滤
并非所有被加载的 Skill 都能最终出现在 Agent 的“工具箱”里。Moltbot 通过一个名为 shouldIncludeSkill 的核心函数(位于 src/agents/skills/config.ts),对每一个 SkillEntry 进行精细的过滤。只有通过所有检查的 Skill,才被认为是“合格”的。
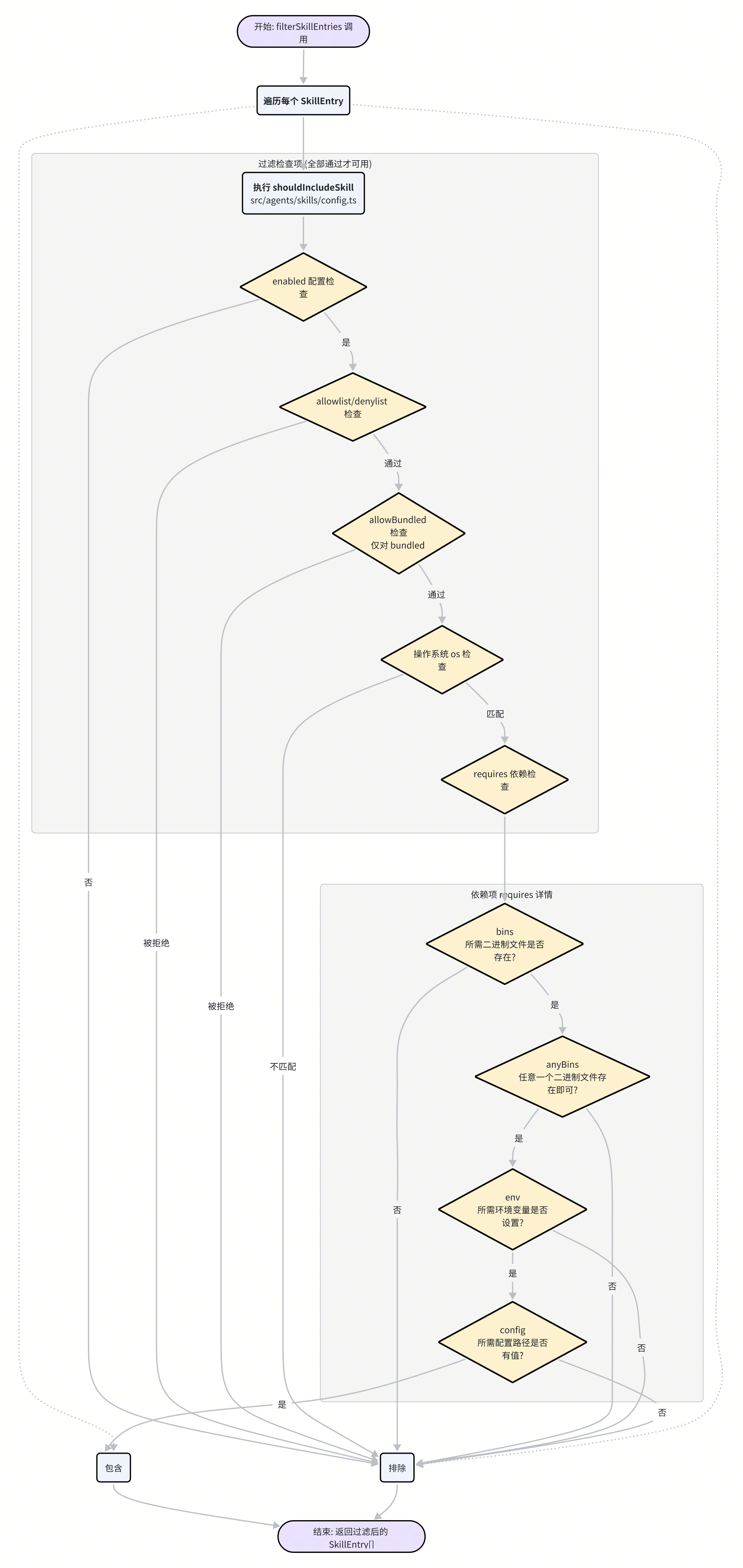
这个过滤流程综合了全局配置、Skill 自身元数据以及当前运行环境的状态,主要包含以下几个关键检查点:
全局开关与列表:
总开关:首先检查
moltbot.json中skills.enabled是否为false。如果是,则所有 Skill 都将被禁用。白名单/黑名单:配置中的
skills.allowlist和skills.denylist提供了最高优先级的控制。如果一个 Skill 的名称在黑名单中,或白名单存在但它不在其中,它将被直接排除。内置 Skill 控制:
skills.allowBundled字段(默认为true)专门用于控制是否加载官方内置的 Skills。这使得用户可以轻松地禁用所有官方 Skill,只使用自己定制的一套。
操作系统匹配:
SKILL.md的 Frontmatter 中可以定义一个os字段,如os: [\"darwin\", \"linux\"]。shouldIncludeSkill会检查当前运行环境的操作系统(process.platform)是否在该列表中。如果不匹配,该 Skill 将被禁用。这对于那些依赖特定系统命令(如 AppleScript)的 Skill 尤其重要。
依赖项检查 (
requires):这是最核心、最精细的检查环节。SKILL.md中的metadata.moltbot.requires字段允许 Skill 声明其运行所需的全部依赖。metadata: moltbot: requires: bins: ["ffmpeg", "yt-dlp"] anyBins: ["python", "python3"] env: ["OPENAI_API_KEY"] config: ["elevenlabs.apiKey"]bins: 数组中的所有二进制文件都必须在系统的PATH中存在。Moltbot 通过eligibility.remote.hasBin()函数进行检查。anyBins: 数组中至少有一个二进制文件存在即可。env: 数组中的所有环境变量都必须已被设置。config: 数组中的所有配置路径(在moltbot.json中)都必须有值。
只有当所有
requires条件都被满足时,Skill 才被认为是可用的。这个机制确保了 Agent 不会尝试去使用一个因缺少依赖而注定会失败的工具,极大地提升了系统的稳定性和可靠性。调用策略 (
invocation):SKILL.md的invocation字段可以控制 Skill 的调用方式。disableModelInvocation: true会让这个 Skill 对 LLM 不可见,即它不会出现在注入到 Prompt 的可用 Skill 列表中,但仍然可以通过command-dispatch机制被用户直接调用。userInvocable: false则相反,它会阻止用户通过斜杠命令等方式直接调用,但 LLM 仍然可以根据需要使用它。
通过这一层层的严格筛选,Moltbot 确保了在任何给定时刻,Agent 的工具箱里都只包含那些确实可用、符合配置且满足所有环境依赖的 Skill。
二、永不落伍:Skill 的动态刷新
在传统的应用中,更改了配置文件或脚本通常需要重启服务才能生效。Moltbot 在 Skill 管理上则实现了更为优雅的动态刷新机制,这主要归功于 src/agents/skills/refresh.ts 中的文件监控与事件系统。
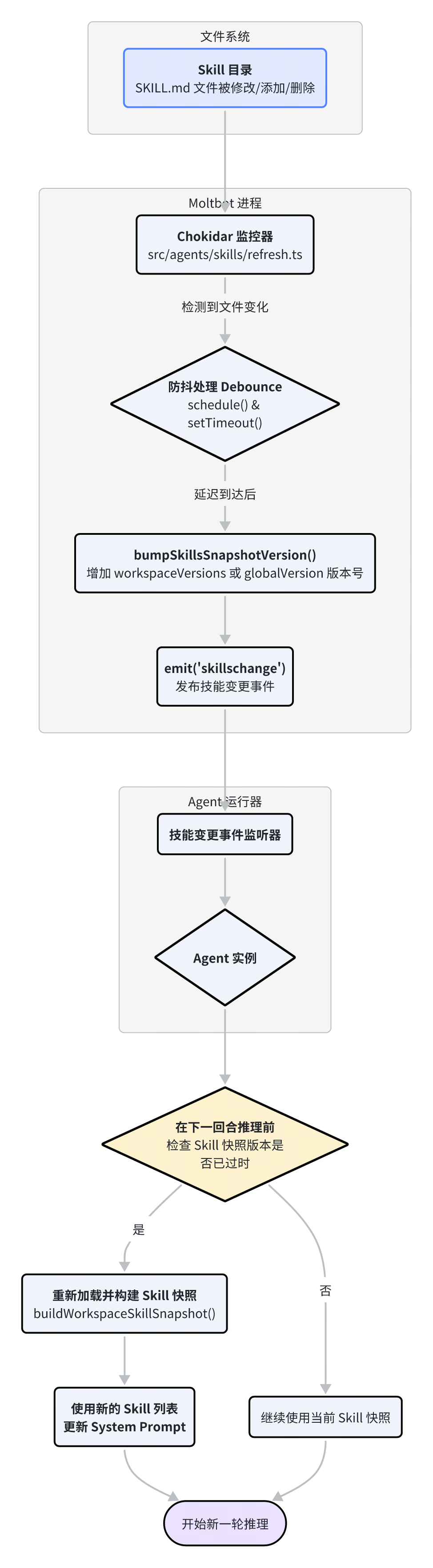
该机制的核心流程如下:
文件监控 (
chokidar):Moltbot 在启动时,会初始化一个
chokidar文件监控器,持续监听所有已知的 Skill 来源目录(工作区、用户级、插件、内置等)。任何对
SKILL.md文件的创建、修改或删除操作,都会被这个监控器捕捉到。
防抖处理 (Debounce):
为了避免因短时间内频繁的文件改动(例如,用户正在编辑文件)而导致系统频繁刷新,Moltbot 实现了一个防抖机制。
当检测到文件变化时,它会启动一个短暂的计时器(默认为 250 毫秒)。如果在计时器结束前又有新的变化发生,则重置计时器。只有当文件系统“安静”了指定时长后,才会执行下一步。
版本号更新:
一旦防抖计时器正常结束,
bumpSkillsSnapshotVersion函数会被调用。这个函数并不会立即重新加载所有 Skill,而是非常轻量地增加一个版本号(
workspaceVersions或globalVersion)。版本号是一个时间戳,确保了其唯一性和单调递增。
发布变更事件:
版本号更新后,系统会通过
emit('skillschange')发布一个全局的技能变更事件。
Agent 响应更新:
Agent 实例在处理下一轮对话之前,会检查当前的 Skill 快照版本号是否落后于全局的版本号。
如果发现版本不一致,说明 Skill 已经发生了变化,此时 Agent 会立即重新调用
buildWorkspaceSkillSnapshot(),加载最新的 Skill 列表,并用其更新自己的 System Prompt。如果版本号一致,则继续使用当前缓存的 Skill 快照。
这个“事件通知 + 延迟加载”的设计非常精妙。它避免了在文件变化时立即进行重量级的加载操作,而是将加载任务推迟到下一次真正需要使用 Skill 的时候,从而实现了极高的响应速度和效率。开发者在本地修改、添加或删除 Skill 后,几乎可以立即在下一轮对话中看到变化,极大地改善了开发和调试体验。
Skill 管线(三):Prompt 构建与命令分发
经过发现、加载和过滤,合格的 Skill 列表已经准备就绪。现在是时候将它们呈现给 Agent,并建立起从用户命令到具体工具执行的桥梁了。本章将揭示 Skill 管线的最后两个关键环节:如何将 Skill 信息构建成 LLM 可理解的 Prompt,以及如何通过 command-dispatch 机制实现高效的命令直达。
一、构建 Agent 的“工具手册”:Skill Prompt 生成
为了让 LLM 知道它有哪些能力(Skill),Moltbot 会动态地生成一段专门的文本,并将其注入到 System Prompt 中。这个过程确保了 Agent 的“知识”总是与当前环境可用的工具保持同步。
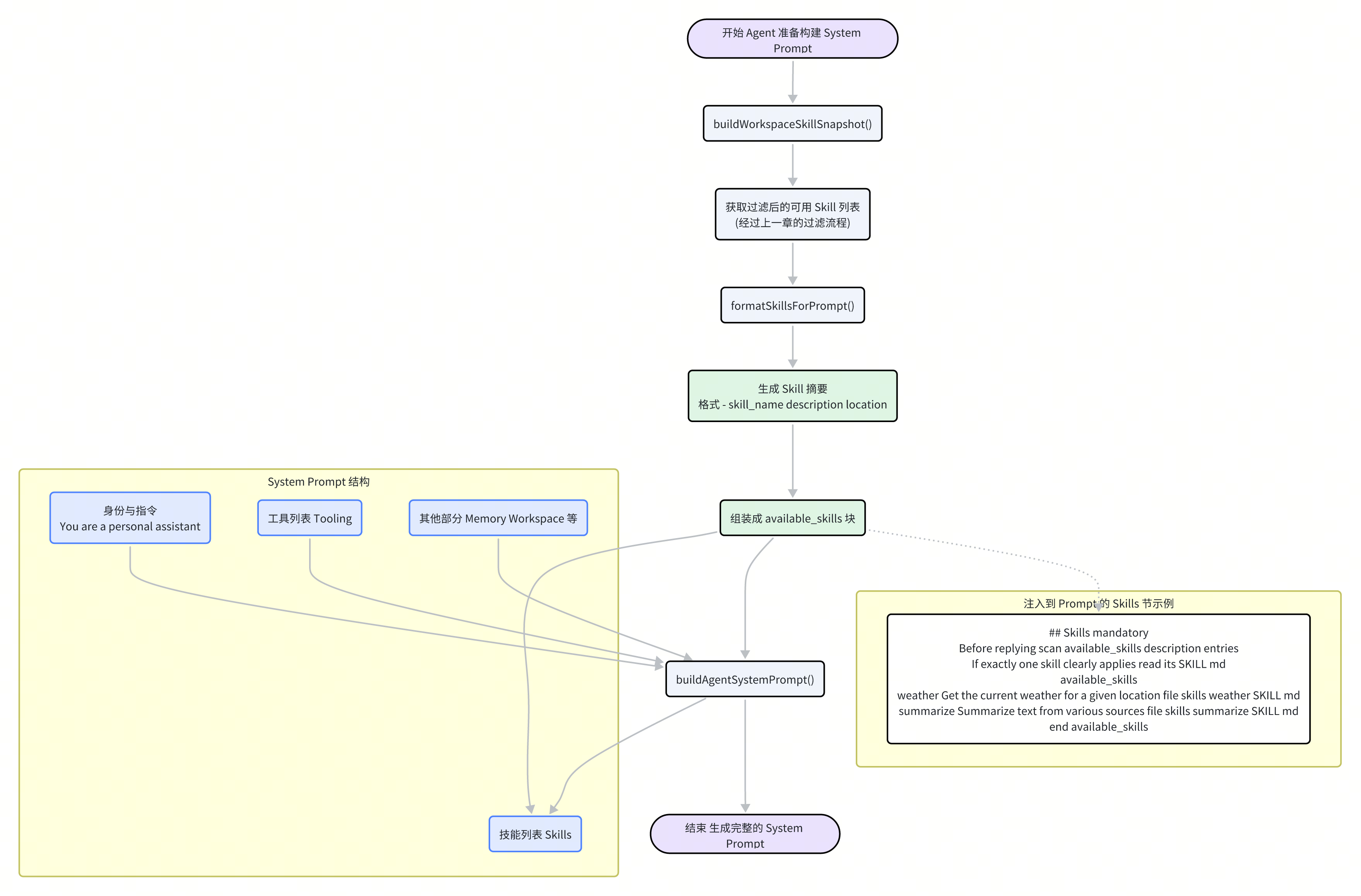
这个构建流程在 src/agents/skills/workspace.ts 的 buildWorkspaceSkillSnapshot 和 src/agents/system-prompt.ts 的 buildAgentSystemPrompt 函数中协同完成。
生成 Skill 快照:首先,
buildWorkspaceSkillSnapshot函数被调用。它接收经过滤后的SkillEntry列表,并执行以下操作:筛选可调用 Skill:排除那些在元数据中标记为
disableModelInvocation: true的 Skill。格式化为 Prompt:调用
@mariozechner/pi-coding-agent包中的formatSkillsForPrompt函数,将每个 Skill 的信息转换成一个标准格式的摘要行。这个摘要通常包含 Skill 的名称、描述以及SKILL.md的文件路径。- <skill_name>: <description> (<location>)组装快照:将格式化后的文本、原始 Skill 列表和版本号一同打包成一个
SkillSnapshot对象。这个快照可以被缓存和传递,避免了重复计算。
注入 System Prompt:接着,在构建总的 System Prompt 时,
buildAgentSystemPrompt函数会获取这个 Skill 快照中的prompt文本,并将其嵌入到 "Skills (mandatory)"(技能,强制性)部分。
最终注入到 System Prompt 中的内容大致如下:
## Skills (mandatory)
Before replying: scan <available_skills> <description> entries.
- If exactly one skill clearly applies: read its SKILL.md at <location> with `read`, then follow it.
- If multiple could apply: choose the most specific one, then read/follow it.
- If none clearly apply: do not read any SKILL.md.
Constraints: never read more than one skill up front; only read after selecting.
<available_skills>
- weather: Get the current weather for a given location. (file:///.../skills/weather/SKILL.md)
- summarize: Summarize text from various sources. (file:///.../skills/summarize/SKILL.md)
- github: Interact with GitHub repositories (issues, PRs, files). (file:///.../skills/github/SKILL.md)
</available_skills>
这段 Prompt 的设计极为关键:
明确的指令:它清晰地告诉 LLM,在使用一个 Skill 之前,必须先用
read工具读取其SKILL.md文件。这是一种“延迟加载”策略,避免了将所有 Skill 的详细说明都塞进 Prompt,极大地节省了宝贵的上下文空间。提供路径:每个 Skill 摘要都附带了其
SKILL.md的绝对文件路径,为read工具的调用提供了直接的目标。决策指导:它还为 LLM 提供了在面对多个或零个适用 Skill 时的决策逻辑,增强了其自主性。
通过这种方式,Moltbot 巧妙地平衡了信息的完备性和上下文的经济性,为 Agent 提供了一本动态更新、按需取阅的“工具手册”。
二、从命令到工具:高效的 Command Dispatch
虽然让 LLM 阅读文档来调用工具非常灵活,但在某些场景下,这种方式显得有些“杀鸡用牛刀”。例如,当用户在 Discord 中输入一个明确的斜杠命令(如 /weather London),我们其实希望系统能直接执行对应的天气查询工具,而不是让 LLM 先进行一番阅读和推理。
为了实现这种高效的“直达”,Moltbot 设计了 command-dispatch 机制。
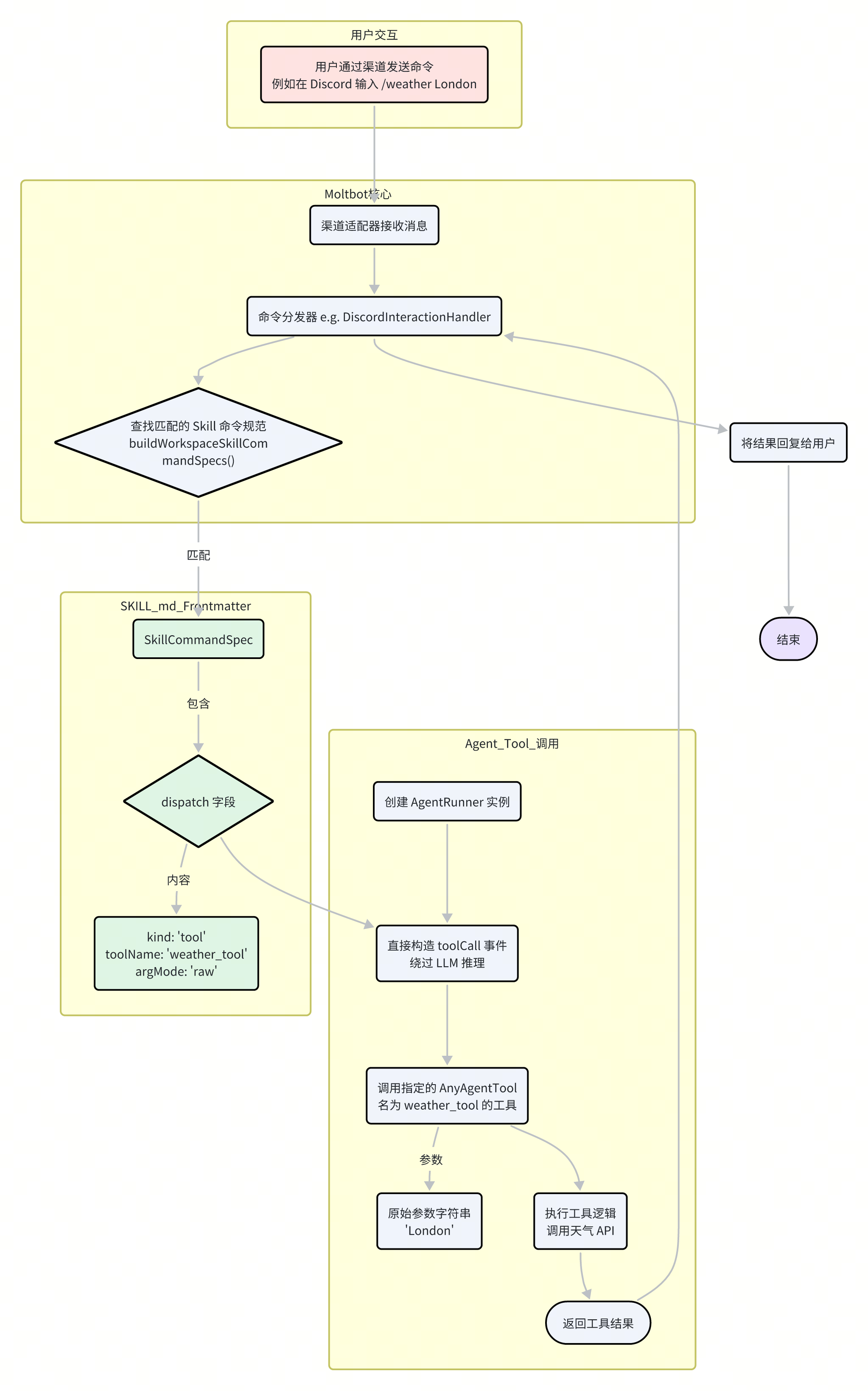
这个机制允许 Skill 的作者在其 SKILL.md 的 Frontmatter 中定义一个直接的命令到工具的映射。
# skills/voice-call/SKILL.md
name: voice-call
description: Manage voice calls via Twilio.
command-dispatch: tool
command-tool: voice_call
command-arg-mode: raw
command-dispatch: tool:声明此 Skill 的命令将直接分发到一个工具。command-tool: voice_call:指定要调用的工具的名称(即AnyAgentTool.name)。command-arg-mode: raw:指示系统将用户提供的所有参数作为一个原始字符串,直接传递给工具。
当一个与 Skill 命令匹配的用户输入(例如,通过 Discord 的斜杠命令或特定渠道的文本命令)到达时,流程如下:
命令匹配:Moltbot 的渠道处理器(如
DiscordInteractionHandler)接收到用户输入,并根据命令名称在buildWorkspaceSkillCommandSpecs生成的命令规范列表中查找匹配项。
检查
dispatch字段:如果匹配到的SkillCommandSpec包含一个dispatch字段,系统便知道需要启动快速分发流程。// src/agents/skills/types.ts export type SkillCommandDispatchSpec = { kind: "tool"; toolName: string; argMode?: "raw"; };绕过 LLM:此时,系统将完全绕过常规的 LLM 推理流程。它不会构建完整的 Prompt,也不会寻求模型的决策。
直接构造工具调用:取而代之的是,它会直接创建一个
toolCall事件,其中包含了dispatch字段中指定的toolName和从用户输入中提取的原始参数字符串。执行工具:这个
toolCall事件被发送给 Agent 的工具执行器,后者找到并运行对应的AnyAgentTool,并将结果返回。
这个 command-dispatch 机制本质上是为高频、确定性的任务开辟的一条“绿色通道”。它极大地降低了响应延迟,减少了不必要的 LLM 调用成本,并提供了如传统 CLI 应用般稳定、可预测的用户体验。
至此,我们完成了对 Moltbot Skill 管线的完整探索。从发现、加载、过滤,到最终的 Prompt 构建和命令分发,这套精心设计的管线共同构成了 Moltbot 灵活、强大且高效的工具使用能力的核心。
插件化架构:扩展核心能力
如果说记忆系统和 Skill 管线是 Moltbot 的“大脑”和“双手”,那么其插件化架构就是赋予它无限可能性的“神经系统”。Moltbot 的设计哲学是保持一个轻量级的核心,同时通过一个强大而灵活的插件系统来扩展其功能。几乎所有非核心的能力,从支持新的聊天平台到集成新的记忆引擎,都是通过插件实现的。本章将深入剖清 Moltbot 的插件化架构,揭示其生命周期、扩展点以及管理机制。
一、插件的生命周期:从发现到激活
一个 Moltbot 插件的生命周期,是从被发现的那一刻起,经过一系列加载、验证和注册步骤,最终将其能力注入到主系统中的过程。这个过程由 src/plugins/loader.ts 中的 loadMoltbotPlugins 函数精心编排。
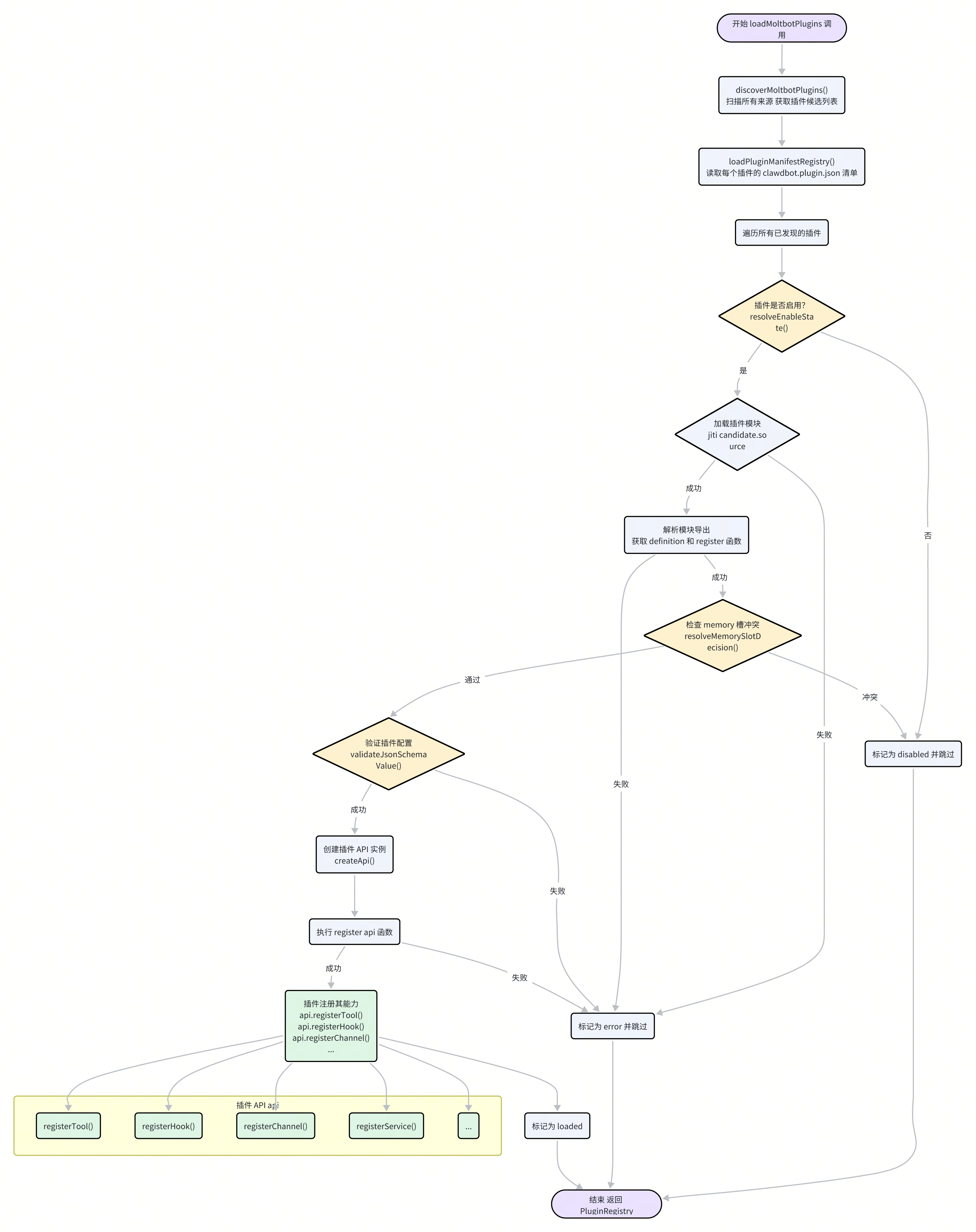
发现 (Discovery):
Moltbot 首先通过
discoverMoltbotPlugins函数扫描一系列预定义的路径(包括工作区、用户配置目录、内置的extensions目录等),寻找潜在的插件。同时,
loadPluginManifestRegistry函数会读取每个候选插件目录下的clawdbot.plugin.json(或moltbot.plugin.json)清单文件。这个 JSON 文件定义了插件的唯一id、类型kind、配置模式configSchema等核心元数据。
加载与验证 (Loading & Validation):
启用检查:根据
moltbot.json中的配置,resolveEnableState函数判断插件是否被启用。被禁用的插件将被直接跳过。模块加载:对于已启用的插件,Moltbot 使用
jiti这个强大的库来即时(Just-In-Time)编译和加载插件的入口文件(通常是index.ts)。jiti的使用使得插件可以用 TypeScript 编写,而无需预先编译成 JavaScript。配置验证:插件的配置会根据其清单文件中定义的
configSchema(一个 JSON Schema 对象)进行验证。如果用户的配置不符合模式,插件加载将失败。
槽位竞争 (Slot Contention):
Moltbot 引入了“槽位”(Slot)的概念,用于管理那些功能互斥的插件。最典型的例子就是
memory槽。系统中同一时间只能有一个记忆插件处于激活状态。resolveMemorySlotDecision函数会检查当前插件是否属于memory类型,并根据配置决定它是否能占据这个唯一的槽位。如果槽位已被其他插件占据,则当前插件将被禁用。
注册 (Registration):
通过所有验证后,插件进入注册阶段。Moltbot 为其创建一个隔离的
MoltbotPluginApi实例。随后,调用插件模块导出的
register(api)函数。这是插件的“入口点”,插件将在这个函数内部,通过调用api对象上的各种方法,来向主系统“宣告”自己的能力。
二、插件 API:能力的注入点
MoltbotPluginApi 是连接插件与核心系统的桥梁。它提供了一系列精心设计的 register* 方法,让插件能够以一种标准化的方式将其功能注入到 Moltbot 的各个部分。

以下是一些最核心的 API 方法:
api.registerTool(toolFactory | tool, options)这是最常用的方法之一,用于向 Agent 的工具箱中添加新的工具(AnyAgentTool)。插件可以注册一个静态的工具对象,也可以注册一个工厂函数,该函数会在每次 Agent 运行时动态创建工具实例,从而访问到当前的会话上下文(如sessionKey)。// extensions/memory-core/index.ts api.registerTool( (ctx) => { const memorySearchTool = api.runtime.tools.createMemorySearchTool({ config: ctx.config, agentSessionKey: ctx.sessionKey, }); // ... return [memorySearchTool, /*...*/]; }, { names: ["memory_search", "memory_get"] }, );api.registerHook(hookName, handler)用于注册生命周期钩子。插件可以通过监听如before_agent_start或agent_end等事件,在 Agent 运行的关键节点执行自定义逻辑。这是实现自动回忆、自动捕获等高级功能的核心。// extensions/memory-lancedb/index.ts api.on("before_agent_start", async (event) => { // ... 实现自动回忆逻辑 });api.registerChannel(channelDefinition)用于集成新的消息平台。插件需要提供一个完整的渠道定义,包括如何发送消息、如何处理入站消息、如何探测连通性等一系列实现。api.registerService(serviceDefinition)用于定义常驻后台服务。如果一个插件需要运行一个长时间存在的进程(例如,一个 Web 服务器或一个持续的监控任务),可以通过此方法注册一个包含start和stop方法的服务。api.registerCli(cliDefinition)允许插件向 Moltbot 的命令行工具(CLI)中添加新的子命令,方便用户通过命令行与插件进行交互。
三、插件的类型 (kind) 与配置
为了更好地管理和分类,每个插件都需要在 clawdbot.plugin.json 中声明自己的 kind。kind 不仅是一个分类标签,它还与特定的系统行为相关联,例如 kind: \"memory\" 的插件会参与 memory 槽位的竞争。
插件的配置同样由 clawdbot.plugin.json 中的 configSchema 定义。Moltbot 的 UI(如 moltbot-control-ui)可以解析这个 Schema,自动为插件生成一个用户友好的配置界面,包括输入框、开关、下拉菜单,并提供帮助提示和输入验证。
// extensions/memory-lancedb/clawdbot.plugin.json
{
"id": "memory-lancedb",
"kind": "memory",
"uiHints": {
"embedding.apiKey": {
"label": "OpenAI API Key",
"sensitive": true
},
"autoCapture": {
"label": "Auto-Capture"
}
},
"configSchema": {
"type": "object",
"properties": {
"autoCapture": { "type": "boolean" }
}
}
}
这种“Schema 驱动配置”的设计,使得插件的开发者只需声明其配置需求,Moltbot 框架便能处理剩下的验证和 UI 生成工作,大大降低了开发复杂性。
总而言之,Moltbot 的插件化架构是其灵活性和可扩展性的基石。通过一个清晰的生命周期管理、一套丰富的 API 扩展点以及一个自描述的配置系统,Moltbot 成功地构建起一个强大的生态系统,使得第三方开发者可以轻松地为其添加几乎任何可以想象到的功能。
案例分析:自定义一个天气查询 Skill 与插件
理论的价值最终体现在实践中。为了将前面章节中讨论的 Skill 管线和插件化架构串联起来,本章将通过一个完整的端到端案例,手把手地展示如何为 Moltbot 添加一个全新的功能:查询实时天气。
我们将创建一个名为 weather 的 Skill,并为其实现一个对应的插件。这个案例将涵盖从定义 Skill、编写插件逻辑、注册工具到最终配置启用的全过程。
整体流程概览
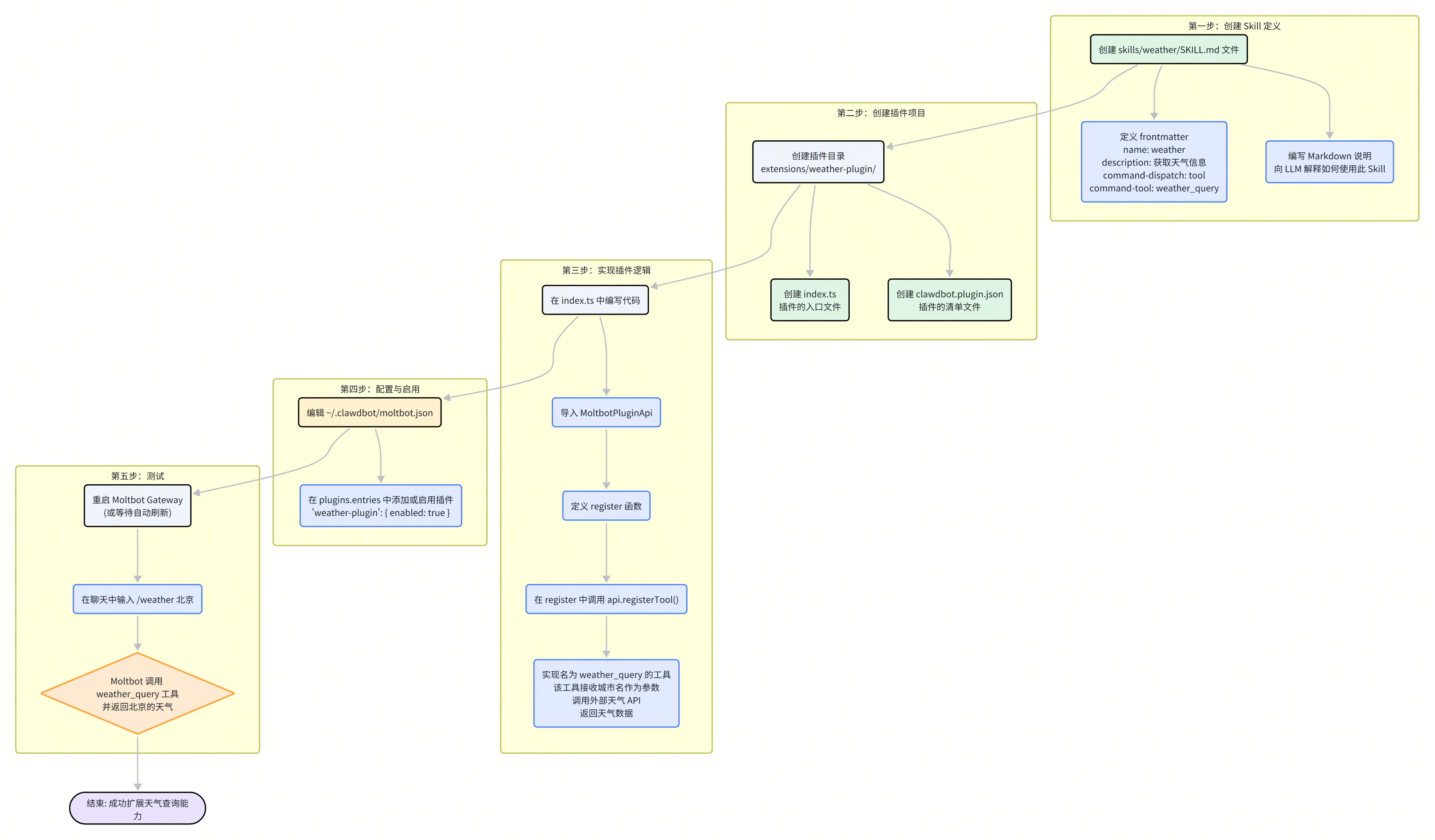
整个过程可以清晰地分为五个步骤:
定义 Skill:创建
SKILL.md文件,告诉系统和 LLM 这个新能力是做什么的。创建插件:建立插件的基本目录结构和清单文件。
实现逻辑:编写插件代码,实现获取天气的具体功能,并将其注册为一个工具。
配置启用:在
moltbot.json中激活我们的新插件。测试验证:重启 Moltbot 并测试新功能。
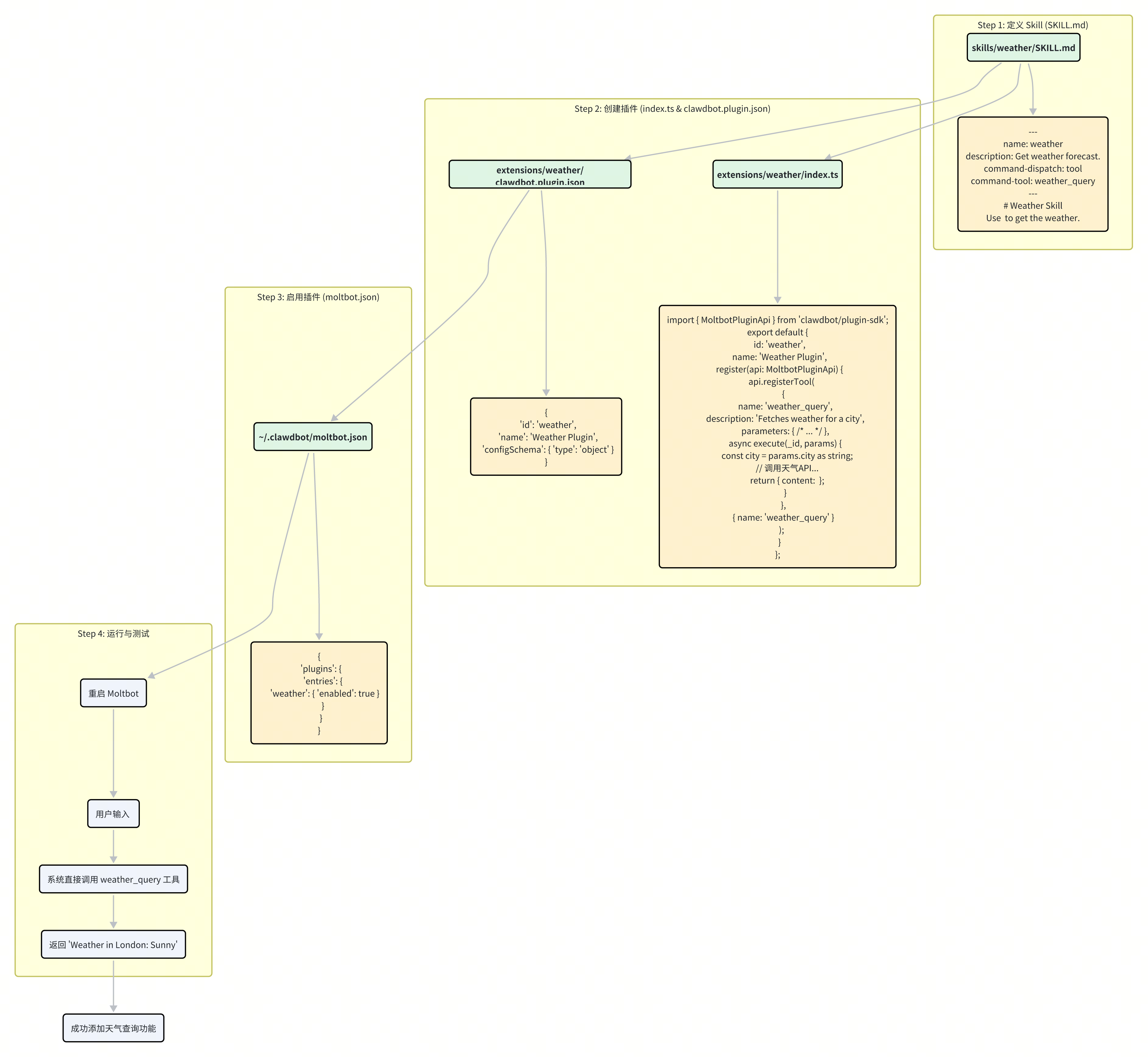
第一步:定义 Skill (SKILL.md)
首先,我们需要在 Moltbot 的一个 Skill 加载路径下(例如,工作区的 skills/ 目录)创建一个新目录 weather,并在其中新建 SKILL.md 文件。
文件路径: <workspace>/skills/weather/SKILL.md
---
name: weather
description: Get the current weather forecast for a specific city.
metadata:
moltbot:
emoji: "☀️"
# ---- 命令直达的核心配置 ----
command-dispatch: tool
command-tool: weather_query
command-arg-mode: raw
---
# Weather Skill
This skill provides current weather information.
## Usage
You can use the `/weather` command to get the weather.
- `/weather <city>`: Gets the weather for the specified city. For example, `/weather Beijing`.
这份 SKILL.md 定义了几个关键点:
name和description提供了基本信息。command-dispatch: tool是这条“绿色通道”的开关,它告诉 Moltbot,凡是匹配到这个 Skill 的命令,都应直接分发给一个工具。command-tool: weather_query指定了该命令要分发到的工具的名称。command-arg-mode: raw指示分发器将命令的所有参数(如 "Beijing")作为一个未处理的原始字符串传递给工具。
第二步:创建插件项目
接下来,我们在 extensions 目录下创建一个 weather 插件。
插件目录: extensions/weather/
我们需要在该目录中创建两个核心文件:
clawdbot.plugin.json: 插件的清单文件,用于声明其 ID 和配置等元数据。{ "id": "weather", "name": "Weather Plugin", "description": "Provides weather query functionality.", "configSchema": { "type": "object", "properties": { "apiKey": { "type": "string", "description": "API key for the weather service." } } }, "required": ["apiKey"] }这里我们声明了插件的
id为weather,并定义了一个必需的配置项apiKey。index.ts: 插件的逻辑入口。
第三步:实现插件逻辑
现在,我们来编写 index.ts 的内容。这是实现天气查询功能的核心。
文件路径: extensions/weather/index.ts
import { Type } from "@sinclair/typebox";
import type { MoltbotPluginApi } from "clawdbot/plugin-sdk";
// 假设我们有一个天气服务客户端
async function getWeatherFromApi(city: string, apiKey: string): Promise<string> {
// 在真实场景中,这里会用 fetch 调用一个天气 API
// const response = await fetch(`https://api.weather.com?city=${city}&apiKey=${apiKey}`);
// const data = await response.json();
// return `The weather in ${city} is ${data.condition}.`;
return `(模拟)${city}今天的天气是:晴,25°C。`;
}
export default {
id: "weather",
name: "Weather Plugin",
register(api: MoltbotPluginApi) {
const config = api.pluginConfig as { apiKey?: string };
const apiKey = config.apiKey;
if (!apiKey) {
api.logger.warn("Weather plugin disabled: apiKey is not configured.");
return;
}
api.registerTool(
{
name: "weather_query", // 工具名称,必须与 SKILL.md 中的 command-tool 匹配
label: "Weather Query",
description: "Fetches the current weather for a given city.",
parameters: Type.Object({
city: Type.String({ description: "The name of the city" }),
}),
async execute(_toolCallId, params) {
const city = (params as { city: string }).city;
try {
const weatherReport = await getWeatherFromApi(city, apiKey);
return { content: [{ type: "text", text: weatherReport }] };
} catch (error) {
return { content: [{ type: "text", text: `Sorry, I couldn't get the weather for ${city}.` }] };
}
},
},
{ name: "weather_query" } // 再次确认工具名称
);
},
};
这段代码做了几件重要的事情:
它在
register函数中从api.pluginConfig获取了用户配置的apiKey。它调用
api.registerTool注册了一个名为weather_query的工具。这个工具的
execute函数接收城市名称作为参数,调用(模拟的)天气 API,并返回结果。
第四步:配置与启用
万事俱备,只欠东风。我们需要在 Moltbot 的主配置文件中启用我们的新插件。
文件路径: ~/.clawdbot/moltbot.json
{
"plugins": {
"entries": {
"weather": {
"enabled": true,
"config": {
"apiKey": "YOUR_SUPER_SECRET_WEATHER_API_KEY"
}
}
}
}
}
我们将 weather 插件的 enabled 设置为 true,并为其提供了必需的 apiKey。
第五步:测试
最后,重启 Moltbot Gateway 以加载新插件和配置。现在,你可以在任何已连接的聊天客户端(如 Discord、Telegram)中测试新功能了。
用户输入:/weather 上海
预期输出:(模拟)上海今天的天气是:晴,25°C。
由于我们在 SKILL.md 中配置了 command-dispatch,整个过程将非常迅速。Moltbot 不会去咨询 LLM,而是直接匹配到 weather 命令,调用 weather_query 工具,并将结果直接返回给用户。
通过这个简单的案例,我们完整地实践了 Moltbot 的扩展机制,深刻地体会到其插件化和 Skill 化设计的强大与优雅。