
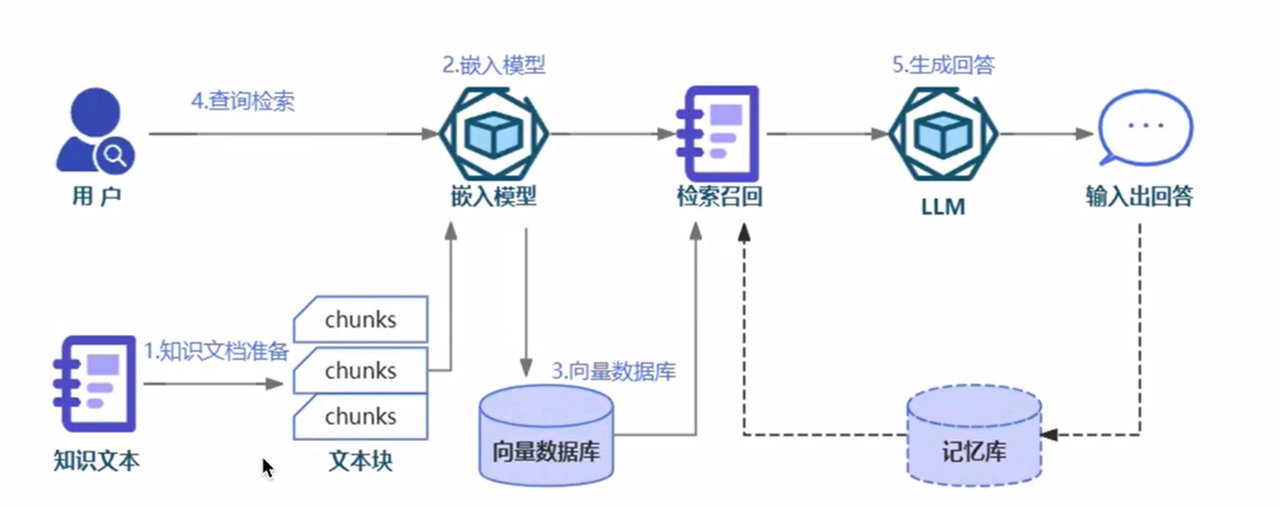
总览
RAG是一个非常精细的活,每个流程节点都可以有很多优化策略,非常不幸的事,有些优化不一定很好,指标不一定能够得到有效提升,而且对于不同类型的文档同一个RAG pipline效果也会截然不同,须结合业务场景针对性的优化
1. 知识文档准备
1.1 数据清洗
高性能RAG系统依赖于准确且清洁的原始知识数据。一方面为了保证数据的准确性,我们需要优化文档读取器和多模态模型。
特别是处理如CSV表格等文件时,单纯的文本转换可能会丢失表格原有的结构。
因此,我们需引入额外的机制以在文本中恢复表格结构,比如使用分号或其他符号来区分数据。另一方面我们也需要对知识文档做一些基本数据清洗其中包括可以包括:
基本文本清理:规范文本格式,去除特殊字符和不相关信息。去除重复文档或冗余信息。
实体解析:消除实体和术语的歧义以实现一致的引用。例如,将“LLM”、“大语言模型”和“大模型”标准化为通用术语。
文档划分:合理地划分不同主题的文档,不同主题是集中在一处还是分散在多处?如果作为人类都不能轻松地判断出需要查阅哪个文档才能来回答常见的提问,那么检索系统也无法做到。
数据增强:使用同义词、释义甚至其他语言的翻译来增加语料库的多样性。
用户反馈循环:基于现实世界用户的反馈不断更新数据库,标记它们的真实性。
时间敏感数据:对于经常更新的主题,删除过期的文档、或者对过期的文档更新。
1.2 分块处理
在RAG系统中,文档需要分割成多个文本块再进行向量嵌入。
在不考虑大模型输入长度限制和成本问题情况下,其目的是在保持语义上的连贯性的同时,尽可能减少嵌入内容中的噪声,从而更有效地找到与用户查询最相关的文档部分。
如果分块太大,可能包含太多不相关的信息,从而降低了检索的准确性。相反,分块太小可能会丢失必要的上下文信息,导致生成的回答缺乏连贯性或深度。
在RAG系统中实施合适的文档分块策略,旨在找到这种平衡,确保信息的完整性和相关性。一般来说,理想的文本块应当在没有周围上下文的情况下对人类来说仍然有意义,这样对语言模型来说也是有意义的。
分块方法的选择
固定大小的分块:这是最简单和直接的方法,我们直接设定块中的字数,并选择块之间是否重复内容。
通常,我们会保持块之间的一些重叠,以确保语义上下文不会在块之间丢失。与其他形式的分块相比,固定大小分块简单易用且不需要很多计算资源。
内容分块
顾名思义,根据文档的具体内容进行分块,例如根据标点符号(如句号)分割。或者直接使用更高级的NLTK或者spaCy库提供的句子分割功能。
递归分块
在大多数情况下推荐的方法。
其通过重复地应用分块规则来递归地分解文本。
例如,在langchain中会先通过段落换行符(\n\n)进行分割。然后,检查这些块的大小。如果大小不超过一定阈值,则该块被保留。对于大小超过标准的块,使用单换行符(\n)再次分割。以此类推,不断根据块大小更新更小的分块规则(如空格、句号)。这种方法可以灵活地调整块的大小。例如,对于文本中的密集信息部分,可能需要更细的分割来捕捉细节;而对于信息较少的部分,则可以使用更大的块。而它的挑战在于,需要制定精细的规则来决定何时和如何分割文本。
从小到大分块
优点:结合了小分块和大分块的优势,通过递归搜索提高检索精度。
方法:将同一文档进行从大到小所有尺寸的分割,并保存每个分块的上下级关系。
缺点:需要更大的存储空间,因为要存储大量重复的内容。
特殊结构分块
适用场景:针对特定结构化内容(如Markdown、Latex文件及各种主流代码语言)。
目的:确保正确地保留和理解文档结构。
工具:langchain提供了专门的分割器来处理这些类型的文档。
分块大小的选择
关键因素:
嵌入模型的最佳输入大小:例如,OpenAI的text-embedding-ada-002模型在256或512大小的块上效果更好。
文档类型和查询复杂性:长篇文章或书籍适合较大的分块以保留上下文连贯性;社交媒体帖子则适合较小的分块捕捉精确语义。
用户查询特点:简短具体的查询适合较小分块,复杂查询可能需要更大分块。
2.嵌入模型阶段
2.1 嵌入模型
可以在huggingface榜单查看
3.向量数据库阶段
3.1 元数据
当在向量数据库中存储向量数据时,某些数据库支持将向量与元数据(即非向量化的数据)一同存储。为向量添加元数据标注是一种提高检索效率的有效策略,它在处理搜索结果时发挥着重要作用。
例如,日期就是一种常见的元数据标签。它能够帮助我们根据时间顺序进行筛选。设想一下,如果我们正在开发一款允许用户查询他们电子邮件历史记录的应用程序。在这种情况下,日期最近的电子邮件可能与用户的查询更相关。然而,从嵌入的角度来看,我们无法直接判断这些邮件与用户查询的相似度。通过将每封电子邮件的日期作为元数据附加到其嵌入中,我们可以在检索过程中优先考虑最近日期的邮件,从而提高搜索结果的相关性。
此外,我们还可以添加诸如章节或小节的引用、文本的关键信息、小节标题或关键词等作为元数据。这些元数据不仅有助于改进知识检索的准确性,还能为最终用户提供更加丰富和精确的搜索体验。
4.查询索引阶段
4.1. 多级索引
元数据无法充分区分不同上下文类型的情况下,我们可以考虑进一步尝试多重索引技术。
多重索引技术的核心思想是将庞大的数据和信息需求按类别划分,并在不同层级中组织,以实现更有效的管理和检索。
这意味着系统不仅依赖于单一索引,而是建立了多个针对不同数据类型和查询需求的索引。
例如,可能有一个索引专门处理摘要类问题,另一个专门应对直接寻求具体答案的问题,还有一个专门针对需要考虑时间因素的问题。这种多重索引策略使RAG系统能够根据查询的性质和上下文,选择最合适的索引进行数据检索,从而提升检索质量和响应速度。
不过为了引入多重索引技术,我们还需配套加入多级路由机制。
多级路由机制确保每个查询被高效引导至最合适的索引。查询根据其特点(如复杂性、所需信息类型等)被路由至一个或多个特定索引。这不仅提升了处理效率,还优化了资源分配和使用,确保了对各类查询的精确匹配。
例如,对于查询“最新上映的科幻电影推荐”,RAG系统可能首先将其路由至专门处理当前热点话题的索引,然后利用专注于娱乐和影视内容的索引来生成相关推荐。
总的来说,多级索引和路由技术可以进一步帮助我们对大规模数据进行高效处理和精准信息提取,从而提升用户体验和系统的整体性能。
4. 2 索引/查询算法
由于向量数据量庞大且复杂,寻找绝对的最优解变得计算成本极高,有时甚至是不可行的。加之,大模型本质上并不是完全确定性的系统,这些模型在搜索时追求的是语义上的相似性——一种合理的匹配即可。从应用的角度来看,这种方法是合理的。
例如,在推荐系统中,用户不太可能察觉到或关心是否每个推荐的项目都是绝对的最佳匹配;
他们更关心的是推荐是否总体上与他们的兴趣相符。
因此查找与查询向量完全相同的项通常不是目标,而是要找到“足够接近”或“相似”的项,这便是最近邻搜索(Approximate Nearest Neighbor Search, ANNS)。这样做不仅能满足需求,还为检索优化提供了巨大的优化潜力。
a. 聚类
当我们在网上购物时,通常不会在所有商品中盲目搜索,而是会选择进入特定的商品分类。
比如“电子产品”或“服饰”,在一个更加细分的范畴内寻找心仪的商品。这个能帮我们大大缩小搜索范围。
同样这种思路,聚类算法可以帮我们实现这个范围的划定。就比如说我们可以用K-mean算法把向量分为数个簇,当用户进行查询的时候,我们只需找到距离查询向量最近的簇,然后再这个簇中进行搜索。
当然聚类的方法并不保证一定正确,如下图,查询距离黄色簇的中心点更近,但实际上距离查询向量最近的,即最相似的点在紫色类
有一些缓解这个问题的方法,例如增加聚类的数量,并指定搜索多个簇。
然而,任何提高结果质量的方法都不可避免地会增加搜索的时间和资源成本。
实际上,质量和速度之间存在着一种权衡关系。我们需要在这两者之间找到一个最优的平衡点,或者找到一个适合特定应用场景的平衡。不同的算法也对应着不同的平衡。
b. 位置敏感哈希
沿着缩小搜索范围的思路,位置敏感哈希算法是另外一种实现的策略。
在传统的哈希算法中,我们通常希望每个输入对应一个唯一的输出值,并努力减少输出值的重复。
然而,在位置敏感哈希算法中,我们的目标恰恰相反,我们需要增加输出值碰撞的概率。
这种碰撞正是分组的关键,哈希值相同的向量将被分配到同一个组中,也就是同一个“桶”里。此外,这种哈希函数还需满足另一个条件:空间上距离较近的向量更有可能被分入同一个桶。这样在进行搜索时,只需获取目标向量的哈希值,找到相应的桶,并在该桶内进行搜索
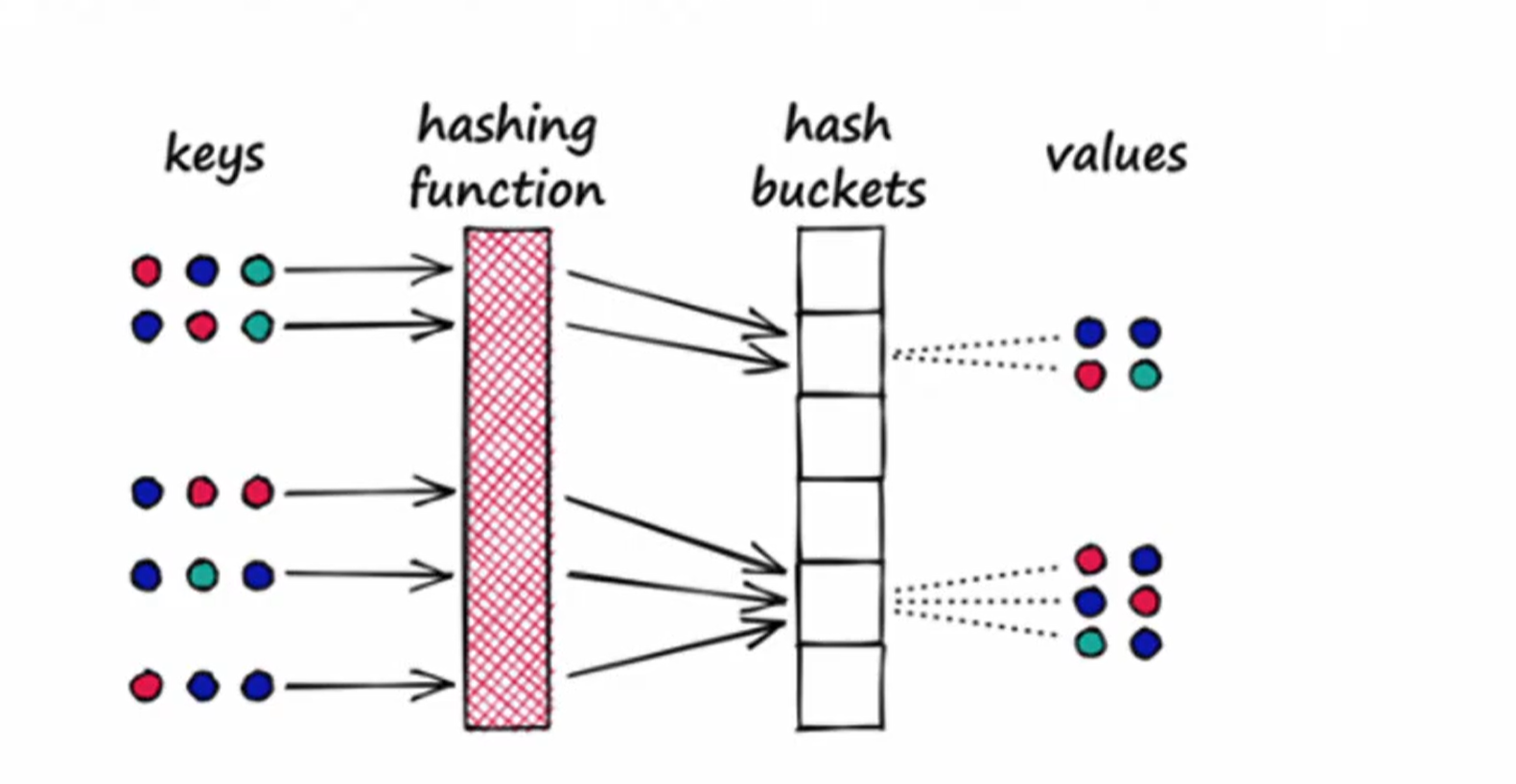
,因此不可能删除数据来减少内存开销,那唯一的选择只能是把每个数据本身大小减小。
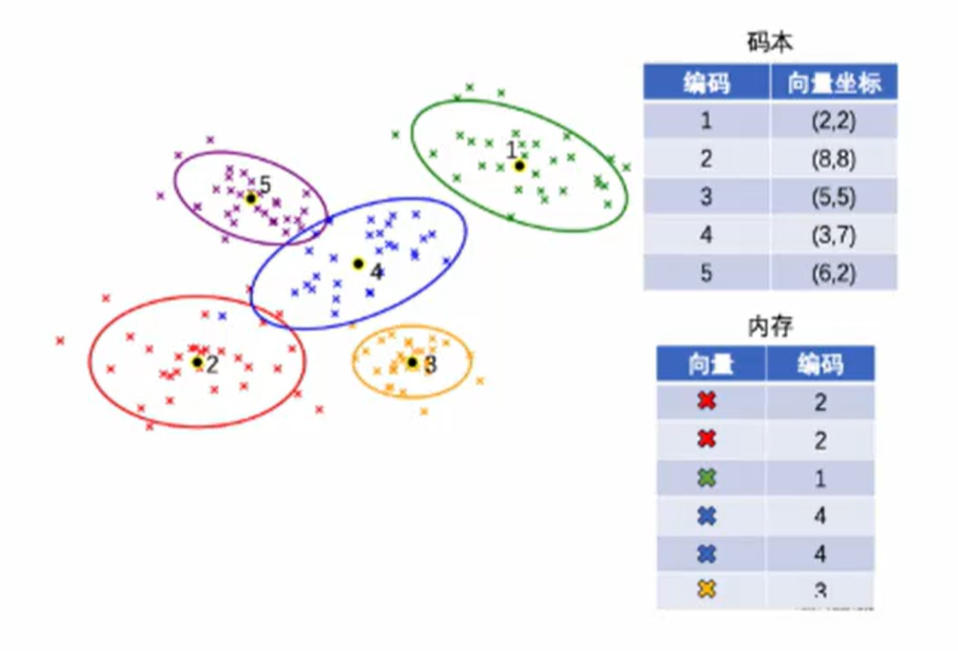
有一种乘积量化的方法可以帮我们完成这点。
图像有一种有损压缩的方法是把一个像素周围的几个像素合并,来减少需要储存的信息。同样我们可以在聚类的方法之上改进一下,用每个簇的中心点来代替簇中的数据点。虽然这样我们会丢失向量的具体值信息,但考虑到聚类中心点和簇中向量相关程度,再加上可以不断增加簇的数量来减少信息损失,所以很大程度上我们可以保留原始点的信息。而这样做带来的好处是十分可观的。
如果我们给这些中心点编码,我们就可以用单个数字储存一个向量来减少存储的空间。而我们把每个中心向量值和他的编码值记录下来形成一个码本,这样每次使用某个向量的时候,我们只需用他的编码值通过码本找到对应的中心向量的具体值。
虽然这个向量已经不再是当初的样子了,但就像上面所说,问题不大。而这个把向量用其所在的簇中心点
可能并不是最重要的考量因素。他们更加关注的是应用的最终效果,也就是回答用户问题的速度和质量。
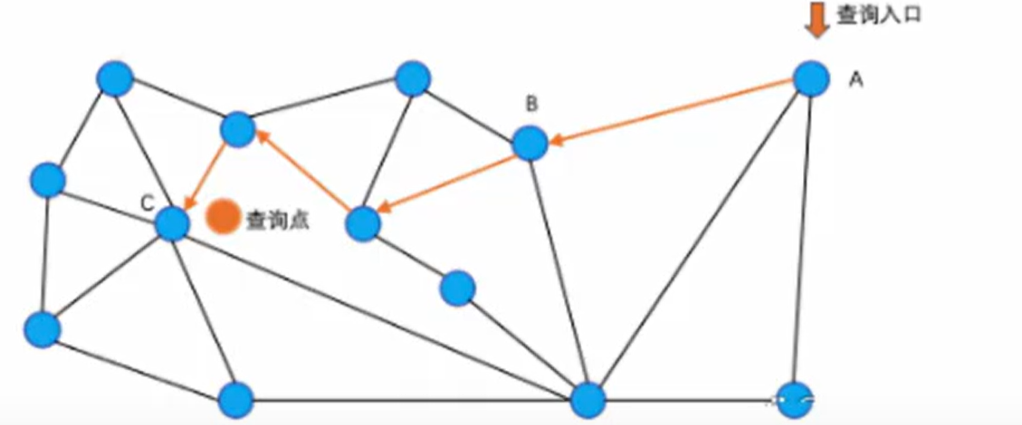
导航小世界(Navigable Small World,NSW)算法正是这样一种用内存换取更快速度和更高质量的实现方式。
这个算法的思路和“六度分割理论”类似——你和任何一个陌生人之间最多只隔六个人,也就是说,最多通过六个人你就能够认识任何一个陌生人。
我们可以将人比作向量点,把搜索过程看作是从一个人找到另一个人的过程。在查询时,我们从一个选定的起始点A开始,然后找到与A相邻且最接近查询向量的点B,导航到B点,再次进行类似的判断,如此反复,直到找到一个点C,其所有相邻节点都没有比它更接近目标。最终这个点C便是我们要找的
相似
向
。
4.3 查询转换
在RAG系统中,用户的查询问题被转化为向量,然后在向量数据库中进行匹配。不难想象,查询的措辞会直接影响搜索结果。
如果搜索结果不理想,可以尝试以下几种方法对问题进行重写,以提升召回效果
a. 结合历史对话的重新
人类来说看似相同的两个问题其向量大小并不一定很相似。我们可以直接利用LLM重新表述问题来进行尝试。
此外,在进行多轮对话时,用户的提问中的某个词可能会指代上文中的部分信息,因此可以将历史信息和用户提问一并交给LLM重新表述。
b. 假设文档嵌入
假设文档嵌入(Hypothetical Document Embedding,HyDE)的核心思想是:
接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。
然后,将这个假设性回复和原始查询一起用于向量检索。
假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
主要关注点:通过为传入查询生成一个假想文档,从而增强和改善相似性搜索。
c. 退后提示(类似lightrag的high level)
如果原始查询太复杂或返回的信息太广泛,可以选择生成一个抽象层次更高的“退后”问题,与原始问题一起用于检索,以增加返回结果的数量。这就是退后提示(Step Back Prompting)的思想。
例如,原问题是“张三在1954年8月至1954年11月期间去了哪所学校?”,这类问题对于LLM来说很容易答错。
但是如果后退一步,站在更高层次对问题进行抽象,提出一个新的问题:“张三的教育历史是怎样的?”
那LLM可以先将张三都列出来,然后将这些信息和原始问题放在一起,那么对于LLM来说就可以很容易给出正确的答案。
d. 多查询检索/多路召回
多查询检索/多路召回(Multi Query Retrieval)也是一种不错的方法。
使用LLM生成多个搜索查询,特别适用于一个问题可能需要依赖多个子问题的情况。
通过上面这些方法,RAG系统能够更精准地处理和响应复杂的用户查询,从而提升整体的搜索效率和准确性。
4.4 检索参数
终于我们把查询问题准备好了,可以进入向量数据库进行检索。在具体的检索过程中,我们可以根据向量数据库的特定设置来优化一些检索参数,以下是一些常见的可设定参数:
a. 稀疏和稠密搜索权重
稠密搜索:通过向量进行搜索。但在某些场景下可能存在限制,此时可以尝试使用原始字符串进行关键字匹配的稀疏搜索。
稀疏搜索算法:一种有效的算法是最佳匹配25(BM25),它基于统计输入短语中的单词频率,频繁出现的单词得分较低,而稀有的词被视为关键词,得分会较高。结合稀疏和稠密搜索可以得出最终结果。
权重比例:向量数据库通常允许设定两者对最终结果评分的权重比例,如0.6表示40%的得分来自稀疏搜索,60%来自稠密搜索。
b. 结果数量(topK)
关键因素:检索结果的数量是另一个关键因素。
覆盖范围:足够的检索结果可以确保系统覆盖到用户查询的各个方面。在回答多方面或复杂问题时,更多的结果提供了丰富的语境,有助于RAG系统更好地理解问题的上下文和隐含细节。
信息过载:但需注意,结果数量过多可能导致信息过载,降低回答准确性并增加系统的时间和资源成本。
c. 相似度度量方法
计算方法:计算两个向量相似度的方法也是一个可选参数。这包括使用欧式距离和Jaccard距离计算两个向量的差异,以及利用余弦相似度衡量夹角的相似性。
余弦相似度:通常,余弦相似度更受青睐,因为它不受向量长度的影响,只反映方向上的相似度。这使得模型能够忽略文本长度差异,专注于内容的语义相似性。
嵌入模型支持:需要注意的是,并非所有嵌入模型都支持所有度量方法,具体可参考所用嵌入模型的说明。
4.5 高级检索策略
a. 上下文压缩
当文档文块过大时,可能包含太多不相关的信息,传递这样的整个文档可能导致更昂贵的LLM调用和更差的响应。
上下文压缩的思想是通过LLM的帮助根据上下文对单个文档内容进行压缩,或者对返回结果进行一定程度的过滤仅返回相关信息。
b. 句子窗口搜索
文档文块太小会导致上下文的缺失。
窗口搜索的核心思想是当提问匹配好分块后,将该分块周围的块作为上下文一并交给LLM进行输出,来增加LLM对文档上下文的理解。
c. 父文档搜索
父文档搜索也是一种很相似的解决方案,先将文档分为尺寸更大的主文档,再把主文档分割为更短的子文档两个层级,用户问题会与子文档匹配,然后将该子文档所属的主文档和用户提问发送给LLM。
d. 自动合并
自动合并是在父文档搜索上更进一步的复杂解决方案。
对文档进行结构切割,比如将文档按三层树状结构进行切割,顶层节点的块大小为1024,中间层的块大小为512,底层的叶子节点的块大小为128。
在检索时只拿叶子节点和问题进行匹配,当某个父节点下的多数叶子节点都与问题匹配上则将该父节点作为结果返回。
e. 多向量检索
多向量检索同样会给一个知识文档转化成多个向量存入数据库,这些向量不仅包括文档在不同大小下的分块,还可以包括该文档的摘要、用户可能提出的问题等,有助于检索的信息。
每个向量可能代表了文档的不同方面,使得系统能够更全面地考虑文档内容,并在回答复杂或多方面的查询时提供更精确的结果。
例如,如果查询与文档的某个具体部分或摘要更相关,那么相应的向量就可以帮助提高这部分内容的检索排名。
f. 多代理检索
定义:多代理检索是将提及的12大优化策略中的部分交给一个智能代理合并使用。
示例:结合子问题查询、多级索引和多向量查询。
子问题查询代理将用户提问拆解为多个小问题。
文档代理对每个子问题进行多向量或多索引检索。
排名代理总结所有检索文档,再交给LLM。
优点:可以取长补短。
子问题查询引擎可能缺乏深度,尤其是在相互关联或关系数据中。
文档代理递归检索在深入研究特定文档和检索详细答案方面表现出色。
注意事项:网络上存在不同结构的多代理检索,具体选取哪些优化步骤尚未有确切定论,需结合使用场景探索。
g. Self-RAG
定义:自反思搜索增强是一个新的RAG框架,通过检索评分和反思评分来提高质量。
主要步骤:
检索:用检索评分评估用户提问是否需要检索,如果需要,LLM调用外部检索模块查找相关文档。
生成:LLM分别为每个检索到的知识块生成答案。
批评:为每个答案生成反思评分,评估检索到的文档是否相关。
最终结果:将评分高的文档作为最终结果一并交给LLM。
4.6 重排模型
在完成语义搜索的优化步骤后,我们能够检索到语义上最相似的文档,但需要注意的是,语义最相似并不总是代表最相关。例如,当用户查询“最新上映的科幻电影推荐”时,可能得到的结果是“科幻电影的历史演变”,虽然从语义上看这与科幻电影相关,但它并未直接回应用户关于最新电影的查询。
为了解决这个问题,可以使用重排(Re-ranking)模型。重排模型通过对初始检索结果进行更深入的相关性评估和排序,确保最终展示给用户的结果更加符合其查询意图。
该过程会考虑更多的特征,如查询意图、词汇的多重语义、用户的历史行为和上下文信息等。以“最新上映的科幻电影推荐”为例,在首次检索阶段,系统可能基于关键词返回包括科幻电影的历史文章、科幻小说介绍、最新电影的新闻等结果。然后,在重排阶段,模型会对这些结果进行深入分析,并将最相关、最符合用户查询意图的结果(如最新上映的科幻电影列表、评论或推荐)排在前面,同时将那些关于科幻电影历史或不太相关的内容排在后面。
这样,重排模型就能有效提升检索结果的相关性和准确性,更好地满足用户的需求。因此,在实践中,使用RAG构建系统时都应考虑尝试重排方法,以评估其是否能够提高系统性能。
5.生成回答阶段
5.1 提示词
大型语言模型的解码器部分通常基于给定输入来预测下一个词。
设计提示词或问题的方式将直接影响模型预测下一个词的概率。通过改变提示词的形式,可以有效地影响模型对不同类型问题的接受程度和回答方式。例如,修改提示语让LLM知道它在做什么工作,是十分有帮助的。
为了减少模型产生主观回答和幻觉的概率,RAG系统中的提示词应明确指出回答仅基于搜索结果,不要添加任何其他信息。例如:
根据场景需要,也可以适当让模型的回答融入一些主观性或其对知识的理解。
使用少量样本(few-shot)的方法,将想要的问答例子加入提示词中,指导LLM如何利用检索到的知识,提升生成内容质量的有效方法。这种方法不仅使模型的回答更加精准,也提高了其在特定情境下的实用性。
5.2 大语言模型
最后一步是LLM生成回答。
LLM是生成响应的核心组件。可以根据需求选择LLM,如开放模型与专有模型、推理成本、上下文长度等。
可以使用一些LLM开发框架来搭建RAG系统,如LlamaIndex或LangChain。这两个框架拥有较好的debugging工具,可以定义回调函数,查看使用的上下文,检查检索结果来自哪个文档等。