
transformer架构
1. 核心概念与背景
起源:首先提到Transformer源于2017年Google的论文《Attention is All You Need》,提出了一种完全基于注意力机制的架构,取代了传统的RNN/CNN。
动机:强调其解决了RNN的长距离依赖问题和训练低效性(无法并行处理序列),同时捕捉全局上下文。
2. 核心模块与技术细节
分模块拆解Transformer,并关联到大模型的实现:
编码器(Encoder)结构
编码器由 N 个相同的层(stack) 堆叠而成,每层包含两个子层:
输入 ──▶ [自注意力层 + 残差连接 + 层归一化] ──▶ [前馈网络 + 残差连接 + 层归一化] ──▶ 输出
多头自注意力层(Multi-head Self-attention) 计算输入序列中每个位置与其他所有位置的关联程度,生成加权表示。
残差连接(Residual Connection) 将输入直接加到子层输出上:output = layer_norm(x + sublayer(x)),防止梯度消失。
层归一化(Layer Normalization) 对每个样本的特征维度进行归一化,加速训练并提高稳定性。
前馈神经网络(Feed Forward Network) 由两个线性层和一个 ReLU 激活函数组成:FFN(x) = max(0, xW₁ + b₁)W₂ + b₂。
解码器(Decoder)结构
解码器同样由N 个相同的层堆叠而成,但每层包含三个子层:
输入 ──▶ [掩码自注意力层 + 残差 + 层归一化] ──▶ [编码器-解码器注意力 + 残差 + 层归一化] ──▶ [前馈网络 + 残差 + 层归一化] ──▶ 输出
掩码自注意力层(Masked Self-attention) 使用掩码(mask)防止关注未来位置,确保解码器只依赖已生成的 token。
编码器 - 解码器注意力层(Encoder-Decoder Attention) 解码器关注编码器输出的相关部分,类似于 seq2seq 模型中的注意力机制。
(1)自注意力机制(Self-Attention)
计算逻辑:
生成 Query、Key、Value 向量
计算注意力权重 通过点积计算 Query 与 Key 的相似度,再通过 softmax 归
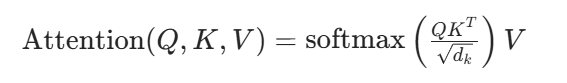
。
加权求和 将归一化后的权重应用到 Value 矩阵上,得到输出序列。
作用:动态计算序列中每个位置对其他位置的依赖权重(例如,处理代词指代问题时,模型能直接关联到远处的名词)。
(2)多头注意力(Multi-Head Attention)
并行化设计:将Q/K/V拆分为多个子空间(如8个头),独立计算注意力后拼接结果。
优势:允许模型在不同子空间学习多样化的特征(例如一个头关注局部语法,另一个关注长距离语义)。
(3)位置编码(Positional Encoding)
问题:自注意力本身无法感知序列顺序。
解决方案:引入正弦/余弦函数或可学习的位置嵌入(如BERT)。
关键点:编码与词向量相加而非拼接,确保位置信息融入语义。
4)前馈网络(Feed-Forward Network)
结构:两层全连接层(如维度扩展至2048再降回512),中间用ReLU激活。
作用:对注意力输出做非线性变换,增强模型表达能力。
(5)层归一化(LayerNorm)与残差连接
残差连接:缓解梯度消失,帮助深层模型训练(如GPT-3有96层)。
LayerNorm:对每层的输入做归一化,稳定训练过程。
Transformer在大模型中的优势
并行计算:自注意力机制允许同时处理整个序列,比RNN的串行计算更高效(适合GPU加速)。
长距离依赖:无论序列长度,任意两位置间直接计算关联(解决RNN的遗忘问题)。
可扩展性:通过堆叠多层(如GPT-3的96层)和增加参数量(如万亿参数),实现复杂模式学习。
实际应用与变体
案例:列举GPT系列(仅用解码器,自回归生成)、BERT(仅用编码器,双向上下文)、T5(编码器-解码器结构)。
优化技术:
稀疏注意力(如Longformer的局部+全局注意力,降低计算复杂度)。
Flash Attention(通过GPU内存优化加速训练)。
模型并行(如Megatron-LM拆分参数到多卡)。
示例回答
我对Transformer的理解主要来自其在BERT、GPT等大模型中的应用。它的核心是自注意力机制,通过计算序列中每个位置对其他位置的权重,解决了RNN的长距离依赖问题。例如在机器翻译中,模型能直接关联源语言和目标语言的对应词,而无需逐步传递隐藏状态。Transformer的并行计算特性使其适合GPU加速,这也是大模型训练的基础。比如GPT-3通过堆叠96层解码器和多头注意力,实现了强大的生成能力。不过,当前Transformer的平方级计算复杂度仍是训练超长序列的瓶颈,因此业界也在研究稀疏注意力或线性注意力等优化方案。
encoder-decoder架构
在Transformer中引入Encoder-Decoder架构是为了处理序列到序列(Seq2Seq)任务(如机器翻译、文本摘要),其核心思想是将输入序列编码为中间表示,再解码为目标序列。这种架构与大模型(如T5、BART)紧密相关,以下是深入解析:
Encoder-Decoder的设计动机
(1)任务需求
输入与输出的解耦:许多任务(如翻译、问答)需要将输入信息整体理解后生成输出,而非逐个词映射。
非对称处理:Encoder专注于压缩输入语义,Decoder负责条件生成(如生成目标语言时需参考源语言编码结果)。
(2)技术优势
双向上下文建模:Encoder可同时看到输入序列的全部位置(如BERT),捕捉全局依赖。
自回归生成:Decoder通过掩码注意力(Masked Attention)逐步生成输出,避免未来信息泄露(如GPT的生成过程)。
Encoder与Decoder的组件差异
以原始Transformer论文为例,对比两者的关键模块:
点击图片可查看完整电子表格
核心组件详解
Encoder的自注意力:
输入:源序列(如英文句子)的嵌入向量。
作用:生成全局语义表示(每个词编码为包含上下文信息的向量)。
Decoder的掩码自注意力:
输入:目标序列(如已生成的部分法语句子)。
掩码机制:确保第t步只能看到前t-1个词(通过上三角矩阵屏蔽未来位置)。
交叉注意力(Cross-Attention):
Query来自Decoder的上层输出,Key/Value来自Encoder的最终表示。
作用:让Decoder在生成每个词时动态关注输入的相关部分(类似“对齐”机制)。
Encoder-Decoder在大模型中的应用
(1)典型模型
T5(Text-to-Text Transfer Transformer):
所有任务统一为文本到文本格式(如翻译、分类均转化为生成任务)。
Encoder处理输入文本,Decoder生成目标文本,通过交叉注意力桥接两者。
BART:
预训练时对输入加噪(如删除、打乱词),Decoder重建原始文本。
适用于生成和理解结合的复杂任务(如摘要、问答)。
(2)与大模型的联系
参数共享:某些模型(如PEGASUS)让Encoder和Decoder共享部分参数,减少计算量。
规模扩展:
Encoder-Decoder结构支持分阶段训练(如先预训练Encoder再微调解码器)。
超大规模模型(如PaLM)通过并行化技术(模型并行、流水线并行)加速训练。
并非所有大模型都使用完整的Encoder-Decoder架构,不同设计对应不同任务:
点击图片可查看完整电子表格
为什么GPT只用Decoder?
任务驱动:GPT专注于生成式任务(如续写文本),需保持自回归特性。
简化架构:移除Encoder减少参数量,更适合单方向生成(但牺牲了对输入的双向理解能力)。
示例回答
Encoder-Decoder架构的核心是将输入理解(编码)与输出生成(解码)解耦。以机器翻译为例,Encoder将源语言句子压缩为包含全局语义的向量,Decoder则基于该向量逐步生成目标语言,每一步通过交叉注意力动态聚焦输入的相关部分。这种设计在大模型中非常关键,比如T5将所有任务统一为文本到文本形式,Encoder处理输入问题,Decoder生成答案。不过,像GPT这类纯Decoder模型更适合生成任务,因为自回归生成更自然,而牺牲了双向上下文的理解。未来,如何平衡Encoder-Decoder的效率与生成质量仍是研究热点。
微调
核心概念与作用
定义:微调是指在预训练模型(Pretrained Model)的基础上,通过特定任务的小规模数据集进行参数调整,使模型适应下游任务。
动机:
利用预训练模型从海量数据中学到的通用知识(如语言理解、图像特征提取)。
避免从头训练大模型的高成本(时间、算力、数据需求)。
关键优势:在少样本(Few-shot)甚至零样本(Zero-shot)场景下快速实现高性能。
微调的关键技术细节
(1) 参数调整策略
全参数微调(Full Fine-tuning):
更新模型所有权重(如BERT微调时调整全部12层参数)。
适用场景:任务与预训练目标高度相关(如文本分类微调BERT)。
部分参数冻结(Partial Freezing):
冻结底层参数(保留通用特征),仅微调顶层(如冻结BERT的前6层,调整后6层)。
优势:减少计算量,防止过拟合(小数据集场景)。
(2) 学习率设置
分层学习率(Layer-wise Learning Rate):
深层参数使用更小的学习率(假设底层已捕捉通用特征,高层需适配任务)。
例如:底层学习率设为1e-5,顶层设为1e-4。
预热(Warmup):初始阶段逐步增大学习率,避免早期梯度不稳定
(3) 数据增强与适配
小数据场景:
通过数据增强(如文本中的同义词替换、图像旋转)扩展训练样本。
使用适配器(Adapter)或LoRA(Low-Rank Adaptation)减少可训练参数(后文详述)。
微调的应用场景与模型案例
(1) 任务类型
分类任务:BERT微调用于情感分析、文本分类(如[CLS]标签输出接分类层)。
生成任务:GPT微调用于对话生成、代码补全(自回归生成 + 任务特定Prompt)。
序列标注:微调BiLSTM-CRF或BERT用于命名实体识别(逐词标注)。
(2) 领域迁移
通用模型 → 垂直领域:
示例:将通用BERT微调为医疗BERT(使用医学文献数据),提升临床术语理解。
方法:领域数据继续预训练(Continual Pretraining)后再微调。
(3) 常见问题
灾难性遗忘(Catastrophic Forgetting):
微调后模型丢失预训练中的通用知识。
解决方案:弹性权重巩固(Elastic Weight Consolidation, EWC)或混合预训练目标。
过拟合:
小数据微调时模型过度拟合噪声。
解决方案:早停(Early Stopping)、Dropout增强、正则化。
计算成本:
全参数微调大模型(如175B GPT-3)需要极高显存。
解决方案:参数高效微调(Parameter-Efficient Fine-tuning, PEFT)。
(4) 参数高效微调技术(PEFT)
Adapter:
在Transformer层中插入小型全连接层,仅训练Adapter参数(冻结原模型)。
参数量减少90%以上,性能接近全参数微调。
LoRA(Low-Rank Adaptation):
用低秩矩阵分解模拟权重变化(ΔW = A×B,A、B为可训练小矩阵)。
适用于大模型(如LLaMA),节省显存且易于部署。
Prefix Tuning:
在输入前添加可学习的“虚拟前缀向量”,引导模型生成目标输出。
示例:微调GPT生成特定风格的文本。
示例回答
微调的核心是利用预训练模型的通用能力快速适配下游任务。例如,用BERT做情感分析时,我们会在预训练的BERT上添加一个分类层,用领域数据调整模型参数。关键技术包括分层学习率(深层参数小步更新)和参数高效方法(如LoRA,避免全参数训练的高成本)。但微调也存在挑战,比如灾难性遗忘——过度调整可能让模型忘记预训练知识,此时可以结合EWC算法约束重要参数的变化。另外,针对大模型,PEFT技术已成为主流,像GPT-3的微调常采用Adapter,仅训练0.1%的参数就能达到接近全参数微调的效果。
deepseek-r1
关于DeepSeek-R1的训练流程和关键技术细节,可结合其多阶段渐进式训练策略与强化学习优化框架,从以下四个层面展开回答:
一、核心训练流程(六阶段迭代)
冷启动阶段(预备阶段)
目标:通过少量高质量数据建立初始推理框架,规范输出格式。
关键操作:
使用3,000条人工修正的“长链思维”(Chain-of-Thought)数据,强制模型按 <推理过程> 和 <摘要> 标签输出结构化内容(如数学分步推导)
数据来源包含数学、编程竞赛题库(如Codeforces)及学术数据集(GPQA)
监督微调(SFT)
数据混合策略:
60万数学推理数据(GRPO生成+过滤)
20万编程解答数据
10万科学推导数据
创新技术:
两阶段微调:先专注推理任务,后扩展至通用任务
引入多Token预测(MTP)提升生成稳定性
推理导向强化学习(RL)
算法核心:Group Relative Policy Optimization (GRPO)
每个问题生成5个候选答案,计算组内奖励均值并优化策略模型
奖励设计:
规则奖励(70%):答案正确性(40%)、推导完整性(30%)、格式规范性(30%)
语言一致性奖励(30%):解决中英文混杂问题
拒绝采样与数据增强
生成100万候选回答,通过奖励模型过滤保留Top 20%高准确样本,并人工审核边界案例
最终合成80万数据(60万推理+20万通用任务),平衡专业性与多样性
通用强化学习
混合奖励机制:
推理任务沿用规则奖励,非推理任务引入偏好模型评估人类对齐性
动态课程学习:任务难度从易到难逐步提升,配合分层KL约束控制策略更新幅度
蒸馏部署
将推理能力迁移至小型模型(如Qwen-1.5B),通过知识蒸馏降低部署成本
二、关键技术细节与优化
数据工程
自生成反馈循环:利用前身模型(如R1-Zero)生成数据,通过自动化验证(代码执行、单元测试)筛选高质量样本
跨领域数据融合:混合医疗、金融等垂直领域数据增强泛化性(如200万医疗数据微调案例)
训练效率优化
混合精度训练:FP16加速计算,FP32保留梯度,显存占用减少50%
梯度检查点:通过重计算中间值降低显存消耗,支持更大批次训练
层级自适应学习率:底层参数低学习率稳定特征,高层参数高学习率快速收敛
安全与稳定性
红队测试:模拟对抗攻击测试模型鲁棒性,通过奖励模型过滤不安全输出
正则化技术:L2正则化与Dropout防止过拟合,提升复杂场景泛化能力